
딥러닝(Deep Learning)이 무엇인지, 어떤 기법이 있는지 알아보고 나서 파이토치(PyTorch) 기본 코딩 스타일을 알아봅니다. 이어서 딥러닝을 수행하는 프로세스와 최소한의 통계 지식, 시각화 기법을 알아봅니다. 빠르게 딥러닝을 알아가는 시간이 될 겁니다.
딥러닝 입문은 총 3개 장입니다. 1장에서 딥러닝 한눈에 살펴보기, 2장에서 인공 신경망 ANN 이해하기, 3장에서 간단한 신경망 만들기를 학습합니다.
간단한 신경망 만들기 ❶
가중치를 이용해 학습하는 신경망을 어떻게 만드는지 사인 함수 예측, 보스턴 집값 예측(회귀 분석), 손글씨 분류(다중분류) 신경망을 만들며 알아봅시다. 이번 장에서는 신경망의 동작뿐 아니라, 실제로 오차를 계산하고 직접 역전파해 가중치를 수정합니다. 또한 이전에 등장하지 않았던 손실 함수인 평균 제곱 오차와 크로스 엔트로피 오차에 대해서 설명합니다.
3장 간단한 신경망 만들기는 총 3편입니다.
2. 보스턴 집값 예측하기 : 회귀 분석
이번에는 파이토치를 사용해 (즉 파이토치가 제공하는 신경망을 사용해) 더 어려운 문제를 해결하겠습니다. 보스턴 집값 데이터는 원래 요소(특징) 81개를 고려한 큰 데이터셋입니다. 우리는 사이킷런(Scikit-Learn)에서 정제해준 14개 요소만을 이용합니다.
💡사이킷런(Scikit-Learn) : 데이터 분석 및 머신러닝용 파이썬 라이브러리. 다양한 데이터셋도 제공해줍니다.
결과를 예측하는 데 사용되는 데이터 요소를 ‘특징(Feature)’이라고 부릅니다. 특징에 모델의 가중치를 반영해 결과를 도출합니다. 이번에는 집값만을 예측하기 때문에 출력은 하나만 나옵니다.
💡특징(Feature) : 딥러닝에서 결과를 예측하는 데 사용되는 데이터 요소. 피처, 특성이라고도 부릅니다.
▼ 실습 예제 소개
- 이름: 보스턴 집값 예측
- 미션: 14개 요인을 분석해 집값을 예측해보자.
- 알고리즘: MLP
- 데이터셋 파일명: Boston Housing
- 데이터셋 소개: 집값에 영향을 미치는 14개 요인을 모아놓은 데이터셋
- 예제 코드 노트
- 위치 : colab.research.google.com/drive/14oW7FqSp0A7TuZkAf0n7flhSUXzaupok
- 단축 URL : http://t2m.kr/4PbEw
- 파일 : ex3_2.ipynb
2.1 데이터 살펴보기
집값에 영향을 미치는 요소는 무엇이 있을까요? 보스턴 집값 데이터셋에서 대표적인 특징으로는 1인당 범죄율, 일산화질소 농도, 주택당 평균 방 개수 등을 제공합니다. 우선 데이터셋을 내려받고 어떻게 생겼는지 살펴보겠습니다.
▼ 보스턴 데이터셋의 특징 출력
from sklearn.datasets import load_boston
dataset = load_boston() # ❶ 데이터셋을 불러옴
print(dataset.keys()) # 데이터셋의 키(요소들의 이름)를 출력
dict_keys(['data', 'target', 'feature_names', 'DESCR', 'filename'])
보스터 데이터셋을 읽어와 출력했습니다. ❶ load_boston( ) 함수로 데이터셋을 불러옵니다. 출력 결과에서 각 키의 의미는 다음과 같습니다.
- data : 우리가 사용할 특징값
- target : 예측할 값. 즉 정답이 있습니다.
- feature_names : 각 특징의 이름
- DESCR : description의 약자로 데이터셋에 대한 전반적인 정보를 제공합니다.
- filename: 데이터셋의 csv 파일이 존재하는 위치
이대로는 처리가 까다롭기 때문에 판다스의 데이터프레임으로 변환해줍니다.
▼ 새로 등장한 함수

💡데이터를 다루는 방법 : 판다스와 PIL
- 데이터에는 다양한 형식 있습니다. 예를 들어 텍스트 파일, 이미지, 동영상, 엑셀 파일 데이터가 있습니다. 파이썬은 이런 데이터를 읽어오는 라이브러리를 제공합니다. 이미지 데이터에는 PIL 라이브러리를, 엑셀 파일처럼 테이블 형식의 데이터에는 판다스 라이브러리를 이용해 읽어옵니다. PIL 라이브러리는 이미지를 읽고 쓰는 것뿐만 아니라, 필터로 영상 효과를 추가하는 기능도 제공합니다. 판다스는 데이터프레임이라는 형태로 데이터를 저장합니다. 데이터프레임은 행렬처럼 데이터를 저장하는 자료구조입니다. 판다스를 이용하면 특정 행 혹은 열을 간단히 삭제 및 추가할 수 있습니다.
2.2 데이터 불러오기
먼저 학습에 사용할 데이터를 준비합시다.
▼ 데이터의 구성요소 확인
import pandas as pd
from sklearn.datasets import load_boston
dataset = load_boston()
dataFrame = pd.DataFrame(dataset["data"]) # ❶ 데이터셋의 데이터 불러오기
dataFrame.columns = dataset["feature_names"] # ❷ 특징의 이름 불러오기
dataFrame["target"] = dataset["target"] # ❸ 데이터프레임에 정답 추가
print(dataFrame.head()) # ❹ 데이터프레임을 요약해서 출력
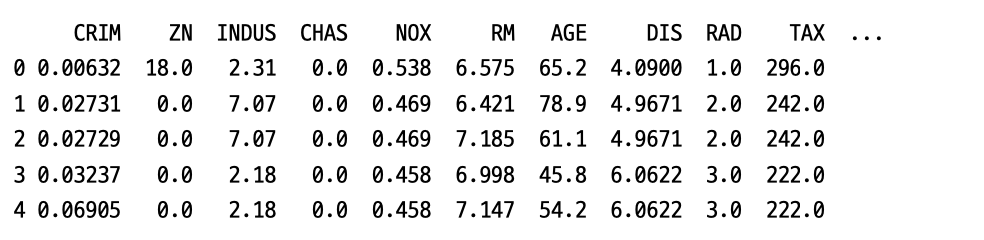
❶ dataset[“data”]는 dataset에서 data 항목만을 가져옵니다. pd.DataFrame( )은 입력받은 데이터를 판다스의 데이터프레임 형식으로 변환합니다. ❷ dataFrame.columns는 열의 이름입니다. 데이터셋의 특징들의 이름(feature_names)을 가져와 저장합니다. ❸ “target”이라는 이름으로 데이터셋의 정답 열을 추가해줍니다. ❹ dataFrame.head( )는 일부 데이터만을 출력해줍니다. 기본값은 5개입니다.
이제 학습에 사용할 데이터 준비가 끝났습니다. 이어서 데이터를 학습할 모델을 준비하겠습니다.
▼ 새로 등장한 함수

2.3 모델 정의 및 학습하기
이번에 사용할 알고리즘은 선형회귀입니다. 선형회귀는 직선을 그려서 미지의 값을 예측하는 가장 간단한 방법입니다. 회귀에 의해 얻은 결과를 실제 데이터와 비교해 오차를 줄여나가는 방식으로 학습합니다. 이때 오차의 제곱에 대한 평균을 취하는 평균 제곱 오차(Mean Square Error, MSE)를 사용합니다. 평균 제곱 오차를 사용하면 작은 오차와 큰 오차를 강하게 대비시킬 수 있어 유용합니다. 학습 루프는 다음과 같습니다.
💡선형 회귀(Linear Regression) : 데이터를 y와 x의 관계를 나타내는 직선으로 나타내는 방법
💡평균 제곱 오차(MSE) : 오차에 제곱을 취하고 평균을 낸 값
▼ 학습 루프
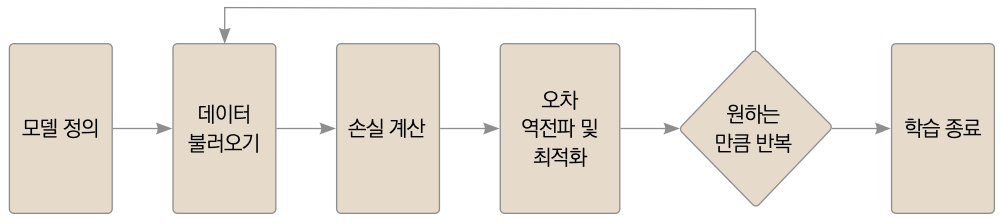
‘1. 사인 함수 예측하기’에서는 직접 함수를 만들어 변수를 지정해줬지만, 이번에는 파이토치에서 제공하는 함수를 활용하겠습니다. torch.nn.Sequential( ) 객체에 모듈(여기서는 선형 회귀 모듈)을 집어넣어주면, 파이토치가 알아서 순서대로 계산합니다. 선형 회귀 모델이므로 파이토치의 nn.Linear 모듈을 이용하면 됩니다. 다음 그림은 선형회귀에 이용할 다층 신경망, 즉 MLP 모델을 나타낸 그림입니다. MLP층은 각 층의 뉴런이 다음 층의 모든 뉴런과 연결되어 있기 때문에 완전연결층(Fully Connected Layer, FC)이라고도 부릅니다.
▼ 선형회귀 MLP 모델
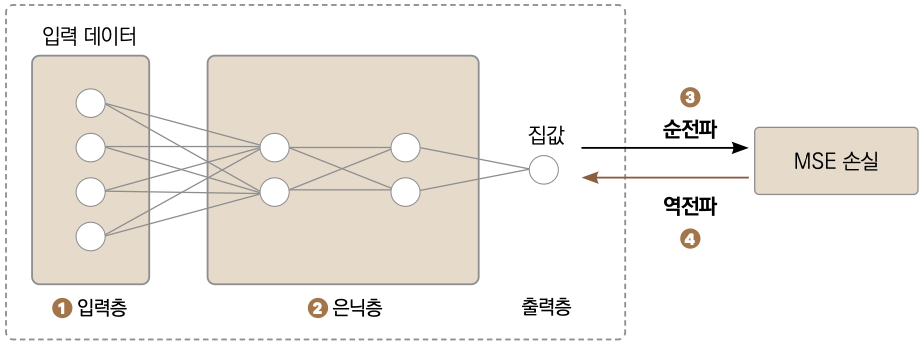
❶ 먼저 입력층에 입력 데이터가 들어옵니다. ❷ 은닉층에 전달된 입력 데이터의 특징으로부터 정보를 추출합니다. ❸ 출력층의 예측값과 실제 정답을 비교해 손실을 계산합니다. 정보가 입력층부터 출력층까지 흘러갔기 때문에 이런 형태를 정보가 순전파됐다고 부릅니다. ❹ 손실을 계산했으면 가중치를 수정하기 위해 오차를 역전파합니다.
신경망을 만들려면 배치와 에포크 개념을 알아야 합니다. 컴퓨터의 메모리는 한정되어 있기 때문에 모든 데이터를 한 번에 처리할 수 없습니다. 따라서 전체 데이터의 나눠서 학습합니다. 이때 떼어서 학습하는 단위가 배치입니다. ‘배치 크기’만큼 학습해서 전체 데이터 모두를 학습하면 ‘1에포크’를 학습했다고 부릅니다. 예를 들어 데이터가 총 1,000개일 때 배치 크기가 100이면, 배치가 10번 반복되어야 데이터 1,000개를 전부 사용합니다. 이를 1에포크의 학습이 이루어졌다고 합니다. 100에포크를 학습한다면 데이터 1,000개 모두를 사용하는 학습을 100번 반복하는 겁니다. 이때 반복 횟수를 이터레이션이라고 부릅니다.
💡배치(Batch) : 딥러닝 모델의 가중치를 업데이트시킬 때 사용되는 데이터의 묶음 단위
💡에포크(Epoch) : 배치 크기 단위로 전체 데이터 모두를 학습하는 단위
💡이터레이션(Iteration) : 1에포크를 완성시는 데 필요한 배치의 반복 횟수
▼ 배치, 에포크, 이터레이션

앞에서 설계한 학습 루프대로 학습 코드를 구현해봅시다.
▼ 선형회귀 MLP 모델 설계
import torch
import torch.nn as nn
from torch.optim.adam import Adam
# ❶ 모델 정의
model = nn.Sequential(
nn.Linear(13, 100),
nn.ReLU(),
nn.Linear(100, 1)
)
X = dataFrame.iloc[:, :13].values # ❷ 정답을 제외한 특징을 X에 입력
Y = dataFrame["target"].values # 데이터프레임의 target값을 추출
batch_size = 100
learning_rate = 0.001
# ❸ 가중치를 수정하는 최적화 함수 정의
optim = Adam(model.parameters(), lr=learning_rate)
# 에포크 반복
for epoch in range(200):
# 배치 반복
for i in range(len(X)//batch_size):
start = i*batch_size # 4 배치 크기에 맞게 인덱스 지정
end = start + batch_size
# 파이토치 실수형 텐서로 변환
x = torch.FloatTensor(X[start:end])
y = torch.FloatTensor(Y[start:end])
optim.zero_grad() # ❺ 가중치의 기울기를 0으로 초기화
preds = model(x) # ❻ 모델의 예측값 계산
loss = nn.MSELoss()(preds, y) # ❼ MSE 손실 계산
loss.backward() # ❽ 오차 역전파
optim.step() # ❾ 최적화 진행
if epoch % 20 == 0:
print(f"epoch{epoch} loss:{loss.item()}")
epoch0 loss:36.82424545288086
epoch20 loss:44.08319091796875
epoch40 loss:41.00265884399414
epoch60 loss:39.553436279296875
epoch80 loss:38.75075149536133
epoch100 loss:38.317203521728516
epoch120 loss:38.06952667236328
epoch140 loss:37.96735763549805
epoch160 loss:37.927337646484375
epoch180 loss:37.95124435424805
❶ 신경망 모델을 정의합니다. nn.Sequential( )에 입력된 층들이 순서대로 계산됩니다. 이번에는 nn.Linear( )와 nn.ReLU( )만을 사용했는데, Linear( )는 MLP 모델을 의미하고 ReLU( )는 활성화 함수의 일종입니다. Linear(13, 100)에서 13은 입력 차원, 100은 출력 차원입니다(13개 특징을 받아 100개 특징을 반환한다는 뜻입니다). 층의 입력과 이전 층의 출력이 일치하지 않으면 에러가 발생하므로 주의해주세요.
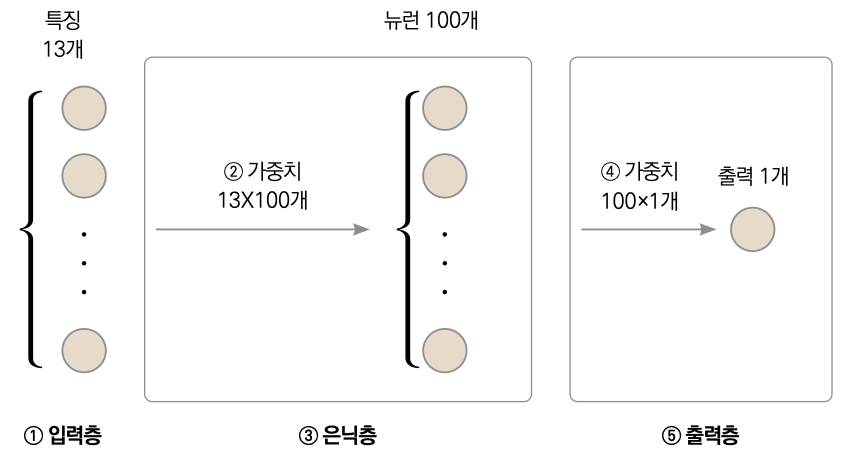
❶ 입력층에 특징 13개가 있습니다. ❸ 은닉층은 뉴런 100개로 구성되어 있으므로 ❷ 가중치는 13×100개(입력 특징 개수 × 은닉층 뉴런 개수)가 필요합니다. ⑤ 출력층 역시 하나의 출력값만을 사용하므로 ❹ 가중치 100×1개(은닉층 뉴런 개수 × 출력값 개수)가 필요합니다.
❷ dataFrame에서 target을 제외한 나머지 값을 X에 입력합니다. dataFrame의 요소들은 특징의 이름으로 호출해야 합니다. 즉 일산화탄소 농도에 관한 데이터를 불러오려면 dataFrame에 “일산화탄소”라는 문자열을 넣어줘야 합니다. 데이터 13개를 X에 입력하고 싶기 때문에 지금 상태로는 문자열 13개를 넣어줘야 합니다. 이렇게 복잡하게 할 필요 없이 특징들의 위치로 값을 불러올 수 있으면 참 편할 겁니다. 그래서 iloc을 이용해 특징들의 이름이 아닌, 위치로 호출할 수 있게끔 해준 뒤, 정답을 제외한 모든 데이터를 불러옵니다.
❸ Adam( )은 가장 많이 쓰이는 최적화 기법입니다. 최적화 기법은 역전파된 오차를 이용해 가중치를 수정하는 기법을 말합니다. 대표적으로 Adam과 경사 하강법이 있습니다. Adam( )은 최적화가 필요한 모델의 가중치들과 학습률을 입력으로 받습니다.
❹ 전체 데이터 크기를 배치 크기(batch_size)로 나누고 나서 시작 지점(i*batch_size)과 끝나는 지점(start+batch_size)을 계산합니다. FloatTensor( )을 사용해서 자료형을 실수형으로 변환해줍니다.
▼ 새로 등장한 함수

❺ 최적화를 실행하기 전, 모든 기울기를 0으로 초기화합니다. 이전 배치에서 계산된 기울기가 남아 있기 때문에 배치마다 초기화해줍시다.
❻ 모델에 입력 데이터를 넣어줍니다.
❼ nn.MSELoss( )는 평균 제곱 오차를 말합니다. 실젯값과 예측값의 차이를 제곱하고, 모든 입력에 대해 평균을 내는 오차를 말합니다. loss.backward( )는 오차를 역전파시킬 기울기를 저장하고 optim.step( )은 최적화 함수에 맞춰 오차 역전파를 수행합니다.
❽에서는 ❼에서 계산한 오차를 역전파합니다. 이 과정에서 모든 가중치에 대한 기울기를 계산합니다.
❾에서는 ❽에서 역전파된 기울기를 이용해 최적화를 진행합니다. 이때 얼마만큼 가중치를 수정하느냐를 결정합니다.
▼ 새로 등장한 함수

처음으로 인공 신경망을 만들어봤습니다만 아직 익숙하지 않은 것 투성이라 어색할 겁니다. 그러나 인간은 적응의 동물, 여러 번 만들다 보면 점점 익숙해지고 나중에는 없이는 못 살 것 같을 겁니다.
2.4 모델 성능 평가하기
학습시키기는 했지만 모델이 정말 예측을 잘하는지 아직 알기 어렵습니다. 모델이 잘 학습됐는지 알아보려면 모델을 시험해야 합니다. 데이터셋에서 행 하나를 추출해 실젯값과 예측값을 비교해봅시다.
▼ 모델 성능 평가
prediction = model(torch.FloatTensor(X[0, :13]))
real = Y[0]
print(f"prediction:{prediction.item()} real:{real}")
prediction:25.572772979736328 real:24.0
실제 집값은 24.0이지만 우리 모델이 예측한 집값은 대략 25.5입니다. 실제 집값과 크게 차이가 나지 않습니다. 더 정확한 결과를 얻고 싶다면 데이터 전처리를 이용해 모든 특징의 범위를 동일하게 하는 등의 추가 조작이 필요합니다.
다음편에서 계속 됩니다.

책 내용 중 궁금한 점, 공부하다가 막힌 문제 등 개발 관련 질문이 있으시다면
언제나 열려있는 <[Must Have] 텐초의 파이토치 딥러닝 특강> 저자님의
카카오채널로 질문해주세요!


