
직접 로지스틱 회귀 분석 모델로 타이타닉 데이터셋을 분석해 생존자를 예측하고 작동 원리를 이해합니다. 또한 분류(Classification) 문제를 예측하고 평가합니다. 총 3편입니다.
로지스틱 회귀 – 타이타닉 생존자 예측하기 ❷
4. 전처리 : 범주형 변수 변환하기( 더미 변수와 원-핫 인코딩)
타이타닉 데이터셋에는 자료형이 object인 변수들, 즉 데이터가 숫자가 아닌 문자인 변수가 4개 있습니다. 기본적으로 머신러닝 알고리즘에서는 문자열로 된 데이터를 이해하지 못합니다. object형까지도 처리해주는 알고리즘 대부분은 object 컬럼들을 숫자 데이터로 변환하는 기능을 제공합니다.
object형을 숫자화해봅시다. 단순하게는 각 값(특정 문자)을 숫자로 대체하는 방법이 있습니다. 가령, 계절이라는 변수의 값으로 봄, 여름, 가을, 겨울이 있다면 각각을 1, 2, 3, 4로 대체하는 방법입니다. 때에 따라서는 이 방법이 효과적일 때도 있으나 기본적으로 지양해야 합니다. 특히나 선형 모델에 이 방법을 사용하면 숫자가 상대적인 서열로 인식됩니다. 즉 봄(1)보다 겨울(4)이 더 큰 개념으로 학습됩니다.
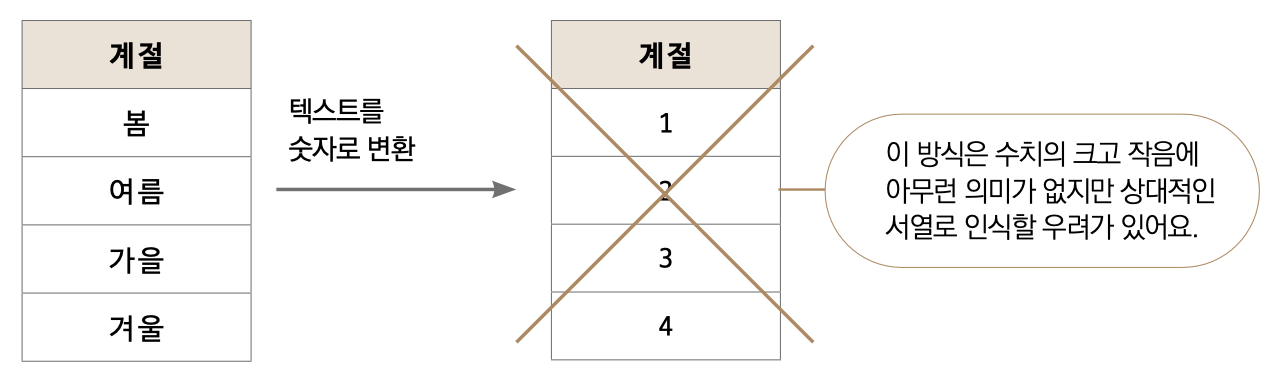
이러한 문제를 피하는 데 더미 변수를 활용합니다. 가장 쉬워보이는 Sex 변수를 가지고 설명하겠습니다. 이 컬럼이 가장 설명하기 쉬운 이유는 값이 male과 female 두 가지뿐이기 때문입니다. 어떻게 변환하는지 아래 테이블을 살펴봐주세요.
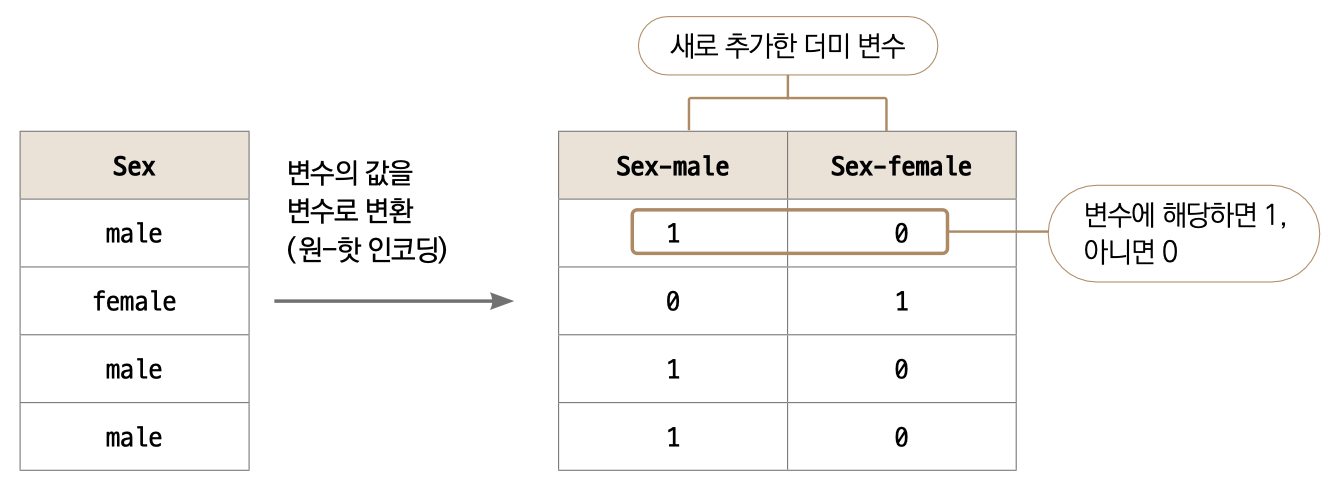
💡더미 변수와 원-핫 인코딩_범주 형태(혹은 문자 형태)의 변수를 숫자로 표현하는 방법으로, 변수에 속해 있는 고윳값에 대한 새로운 변수들을 만들어 0과 1로 표현합니다.
기존에 하나던 컬럼을 각 male과 female 컬럼으로 분리했습니다. 그리고 하나에서 두 개로 늘어난 컬럼에는 변수에 해당하면 1, 해당하지 않으면 0을 숫자로 채웠습니다. 머신러닝에서는 이런 식으로 문자로 된 값을 숫자화하여 이해할 수 있게 됩니다. 이런 식으로 변환하는 것을 ‘더미(Dummy) 변수를 만든다’, 혹은 원-핫 인코딩(One-hot encoding)이라고 합니다.
Sex에는 값이 male과 female 두 가지 뿐이라 더미 변수 2개가 만들어졌습니다. 그럼 봄, 여름, 가을, 겨울 값이 있는 계절은 어떻게 될까요? 당연히 값 종류만큼 4개 컬럼이 생성되어야 합니다. 원-핫 인코딩을 할 때 한 가지 고려할 사항이 있습니다. 예를 들어 값이 수백 수천 가지라면 어떻게 할까요? 새로운 컬럼을 수백 수천 개나 만들어야 할까요? 정말 중요하면 어떤 수단을 써서라도 숫자화해야겠지만, 그렇지 않다면 데이터에서 제외시키거나 다른 방법으로 처리하는 것이 좋습니다.
타이타닉 데이터셋에 있는 object들을 살펴봅시다. Name, Sex, Ticket, Embarked입니다. 각 변수마다 고윳값이 몇 가지인지 살펴보겠습니다. nunique( ) 함수로 고윳값 개수를 확인할 수 있습니다. Name부터 하나씩 살펴보겠습니다.
data['Name'].nunique( )
889
data['Sex'].nunique( )
2
data['Ticket'].nunique( )
680
data['Embarked'].nunique( )
3
Sex에는 이미 알다시피 두 가지 값이 있고, Embarked(승선한 항구)도 3개로 그리 많지 않습니다. 전혀 부담되지 않는 수준입니다. 하지만 Name이나 Ticket은 상황이 좀 다릅니다. 고윳값이 수백 가지라서 더미 변수로 변환시키면 그 수만큼 컬럼이 생깁니다. 여기서 이 변수들이 결과를 도출하는 데 꼭 필요한지를 고민해보아야 합니다. 우선은 이름에 따라 사망 여부가 갈린다고 추론하기는 어렵기 때문에 Name 변수를 큰 고민 없이 제외시킬 수 있습니다. Ticket은 티켓 번호입니다. 중요할 수도 있지만, 이미 Pclass(티켓 클래스)와 컬럼을 가지고 있기 때문에 굳이 Ticket 변수로 무언가 얻어낼 필요는 없을 것 같습니다.
따라서 우리는 Name과 Ticket 변수를 데이터에서 제외하고, 남은 두 object형을 원-핫 인코딩하겠습니다. 우선 drop( ) 함수를 사용하여 Name과 Ticket을 제거하고 head( ) 함수로 제대로 제거되었는지 확인해봅시다.
data = data.drop(['Name','Ticket'], axis=1)
data.head( )
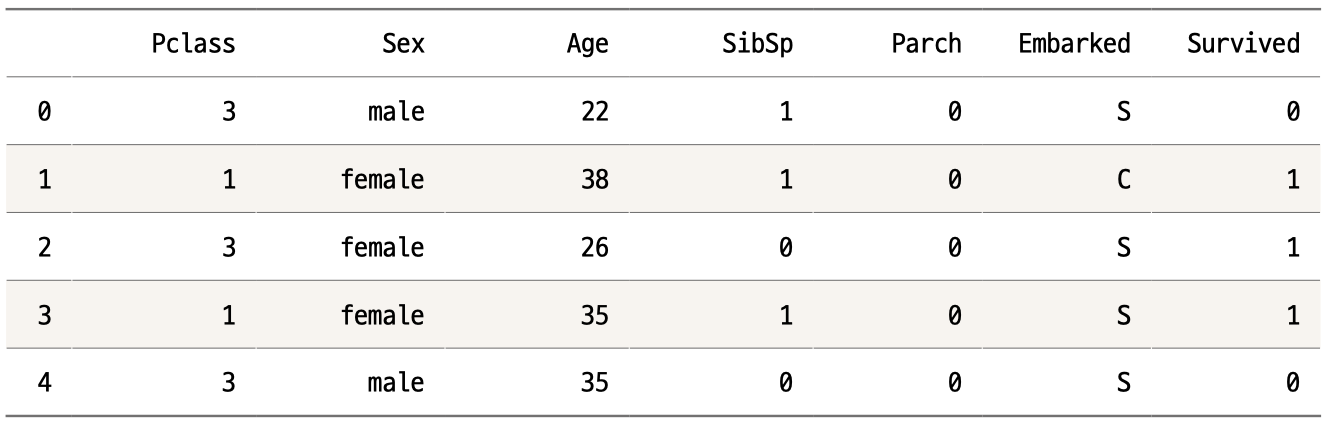
이제 판다스의 get_dummies( ) 함수를 사용하여 문자 형태의 변수들을 원-핫-인코딩해보겠습니다.
pd.get_dummies(data, columns = ['Sex','Embarked'])
괄호 안에 데이터 프레임(여기서는 data)을 먼저 써주시고, columns라는 매개변수에 변환시킬 컬럼명을 리스트 형태로 넣으면 됩니다. 그럼 다음과 같은 결과물을 얻게 됩니다. 참고로 이 코드의 결과를 data에 저장하지는 않습니다. 변환된 모습만 출력했습니다.
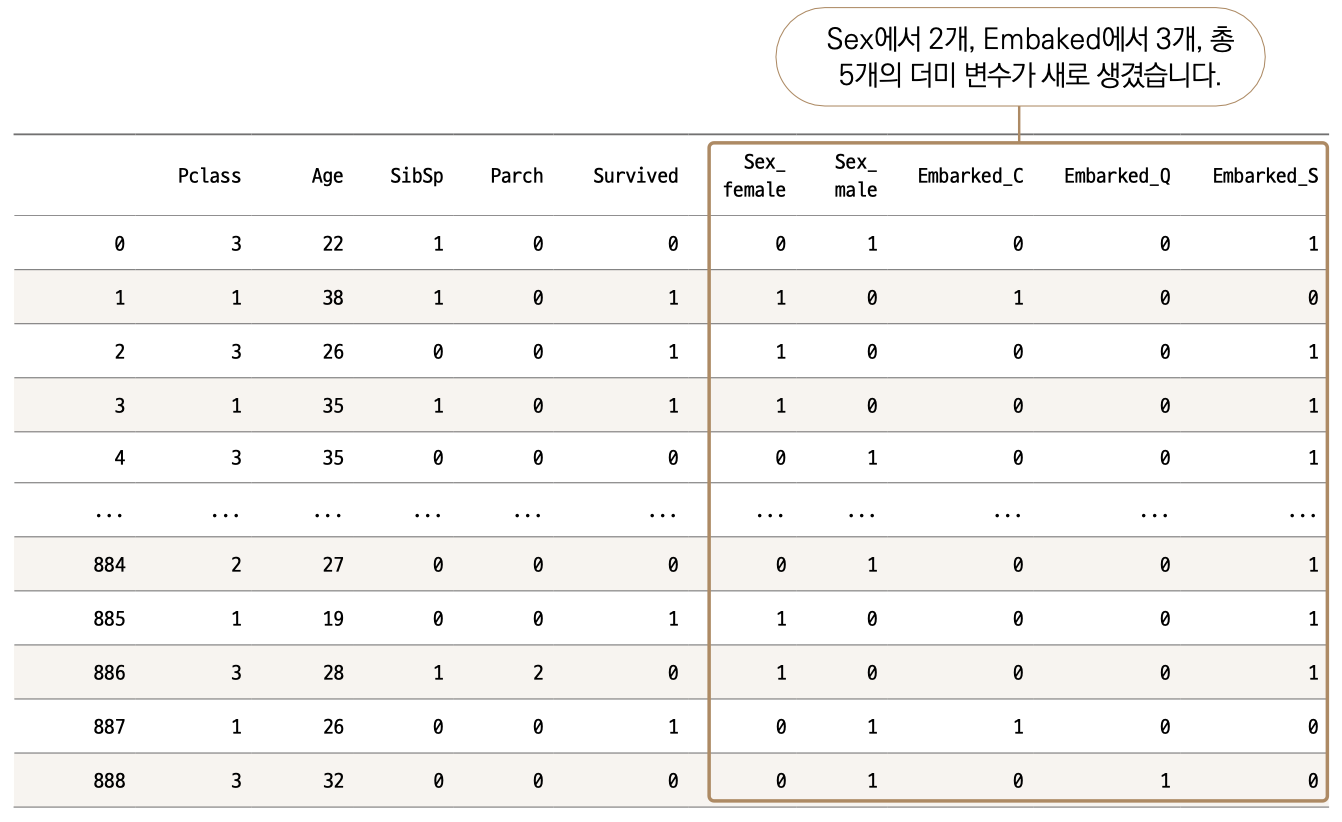
예상대로 Sex에서 2개, Embaked에서 3개, 총 5개의 컬럼이 오른쪽에 새로 생겼습니다. 더미 변수가 생기면서 기존에 있던 Sex와 Embarked 컬럼(변수)는 사라졌습니다. 여기서 한 단계만 더 나아가보겠습니다. Sex는 Sex_female과 Sex_male로 분리되었죠. 과연 둘 다 필요할까요?
예를 들어 Sex_male이 0이면 당연히 이 승객은 female에 해당합니다. 둘 중 하나만 남겨도 구분이 가능하겠군요. Embarked도 마찬가지입니다. Embarked_Q와 Embarked_S가 모두 0이면 Embarked_C에 해당하는 승객입니다. 즉, 우리는 더미 변수에서 고윳값 개수보다 하나를 덜 사용해도 구분하는 데 문제가 없습니다. 이렇게 컬럼 개수를 줄여주면 데이터 계산량이 줄어듭니다. 우리가 테이블을 눈으로 확인할 때도 조금이나마 부담을 줄일 수 있습니다. get_dummies( ) 함수는 이 기능도 제공합니다. drop_first 매개변수를 추가하면 됩니다.
pd.get_dummies(data, columns = ['Sex','Embarked'], drop_first = True)
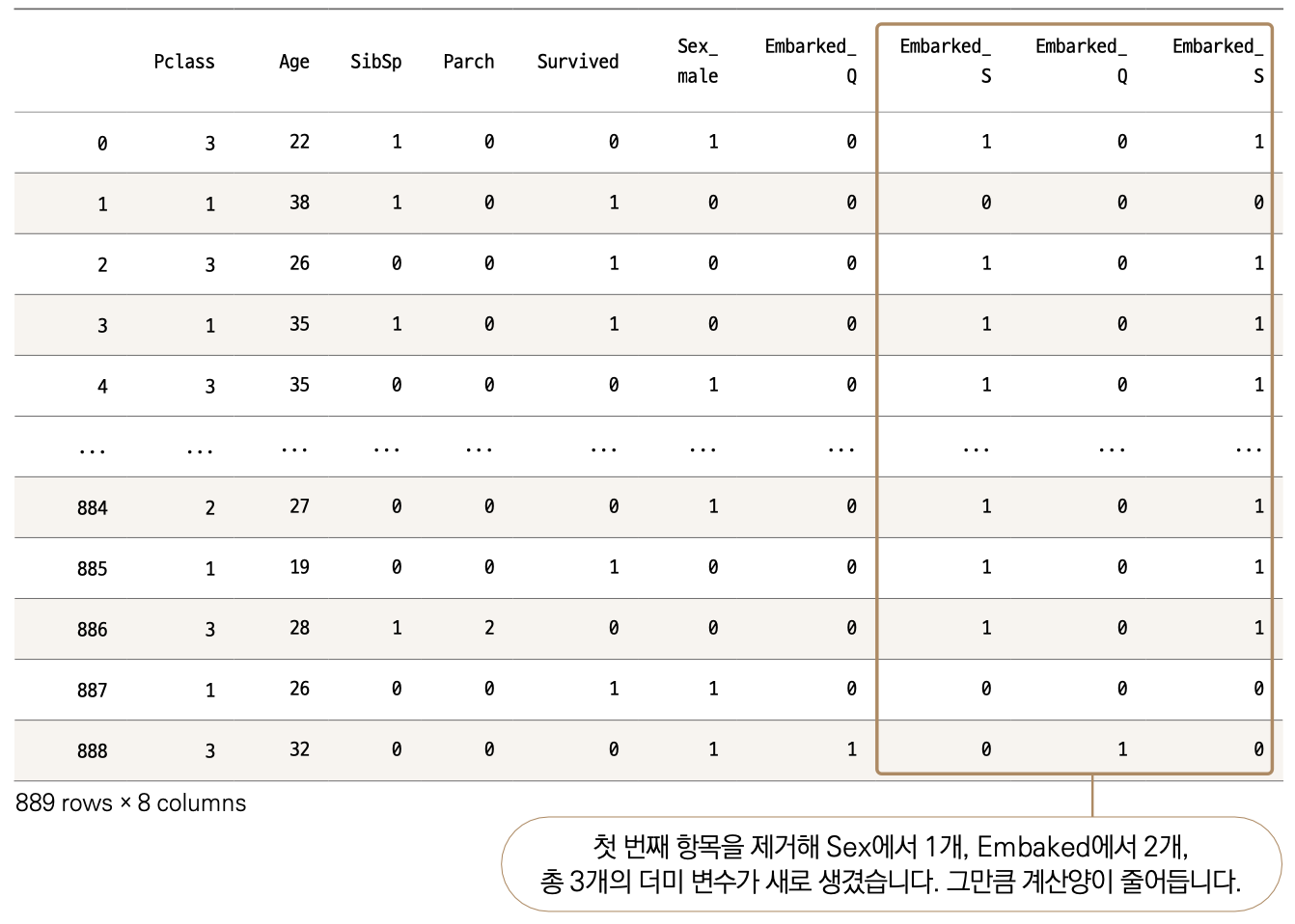
기존에는 10개 컬럼이 출력되었는데, 8개로 줄어든 모습입니다. 다만, 앞서 말씀드렸다시피 이 코드는 변환된 모습을 보여줄 뿐 data에 저장하지 않습니다. data에 최종 데이터를 저장해줍시다.
data = pd.get_dummies(data, columns = ['Sex','Embarked'], drop_first = True)
5. 모델링 및 예측하기
모델링하기에 앞서 독립변수와 종속변수, 그리고 훈련셋과 시험셋으로 나누어주겠습니다.
from sklearn.model_selection import train_test_split
X = data.drop('Survived', axis = 1) # 데이터셋에서 종속변수 제거 후 저장
y = data['Survived'] # 데이터셋에서 종속변수만 저장
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 100) # 학습셋, 시험셋 분리
로지스틱 회귀 분석 모듈은 선형 회귀 분석과 마찬가지로 sklearn.linear_model에서 불러올 수 있습니다.
from sklearn.linear_model import LogisticRegression # 로지스틱 회귀 임포트
model이라는 이름 안에 로지스틱 회귀 분석 속성을 부여하고, fit( ) 함수로 훈련시킵니다.
model = LogisticRegression() # 로지스틱 회귀 모델 생성
model.fit(X_train, y_train) # 모델 학습
예측하는 함수 또한 동일하게 predict( ) 를 사용합니다.
pred = model.predict(X_test) # 예측
6. 예측 모델 평가하기
이번 데이터 목푯값은 0과 1로 나누어진 이진분류(Binary classification)이기 때문에 RMSE는 평가에 적합하지 않습니다. 다양한 이진분류 평가 지표로는 정확도(Accuracy), 오차 행렬, 정밀도(Precision), 재현율(Recall), F1 Score, 민감도, 특이도, AUC 등이 있습니다.
그중 가장 간단한 정확도를 사용하겠습니다. 정확도는 예측값과 실젯값을 비교하여 얼마나 맞추었는지를 확인하는 겁니다. 즉 시험셋 100개를 예측하고, 그중 90개를 정확히 맞췄다면 정확도는 0.9가 되고, 모두 맞추면 1.0이 됩니다.
from sklearn.metrics import accuracy_score # 정확도 라이브러리 임포트
accuracy_score(y_test, pred) # 실젯값과 예측값으로 정확도 계산
0.7808988764044944
sklearn.metrics에서 평가 모듈을 불러왔습니다. accuracy_score( ) 에 실젯값과 예측값을 매개변수로 넣어주면 됩니다. 결과를 보면 약 78% 정도의 정확도를 보입니다. 그렇게 나쁜 수준은 아니지만, 그렇다고 엄청 잘 예측하는 모델이라 할 수는 없습니다.
정확도의 좋고 나쁨을 결정하는 절대적인 지표는 없습니다. 이는 처한 상황에 따라 다르게 고려되어야 합니다. 예를 들어 예측하려는 종속변수의 고윳값이 2개가 아닌 10개라면 상대적으로 더 낮은 정확도도 용인될 수 있습니다. 또한 고윳값이 2개인 이진분류에서도 각각의 비율이 어떠한가에 따라 평가 기준이 달라집니다. 가령 0이 95%이고 1이 5%로 구성된 이진분류라면, 정확도가 90%이더라도 좋은 값이라고 볼 수 없습니다. 왜냐하면 이 경우는 머신러닝 모델 없이 모든 값을 0으로 예측하는 편법을 써도 정확도는 95%가 나올 수 있기 때문입니다. 만약 이진분류에서 고윳값이 비슷한 비율로 (약 50:50) 분포되어 있다면, 80% 이상의 정확도 정도면 나쁘지 않다고 보고, 90% 이상의 정확도를 얻어야 괜찮은 결과로 보는 편입니다. 타이타닉 데이터의 경우는 높은 정확도를 기대할 수 있는 조건이기 때문에 78%의 정확도는 아쉬움이 많이 남는 결과입니다. 향후 배울 XGBoost나 LightGBM을 사용하면 더 좋은 정확도를 얻을 수 있을 겁니다.
어떤 변수가 어떤 영향을 미쳤는지 계수를 통하여 확인해봅시다. 방법은 ‘선형 회귀’와 거의같습니다. 약간 다른 점이 있어 설명드리겠습니다. 다음은 선형 회귀 분석에서 확인했던 model.coef_의 결과물입니다.
array([2.59757578e+02, 1.82169249e+01, 2.77903898e+02, 4.61169867e+02, 2.39817410e+04])
그럼 로지스틱 회귀 분석 모델의 계수도 확인하겠습니다.
model.coef_
array([[-1.18222701, -0.03992812, -0.32136451, 0.00796449, -2.56868467, -0.07899451, -0.23563186]])
다른 점을 발견했나요? 선형 회귀에서는 array( )안에 리스트가 [ ]로 된 반면, 이번에는 2중 리스트 형태인 [[ ]]입니다. 선형 회귀에서와 같이 다음 코드로 실행하면 에러가 발생합니다.
# X의 컬럼을 사용해 판다스 시리즈로 변환
pd.Series(model.coef_, index = X.columns)
--------------------------------------------------------------------------- ValueError Traceback (most recent call last) <ipython-input-25-4374cac64b97> in <module>()
----> 1 pd.Series(model.coef_, index = X.columns)
1 frames
/usr/local/lib/python3.7/dist-packages/pandas/core/common.py in require_length_
match(data, index)model.coef_
array([[-1.18222701, -0.03992812, -0.32136451, 0.00796449, -2.56868467,
-0.07899451, -0.23563186]])530
531
--> 532
533
534
if len(data) != len(index):
raise ValueError(
"Length of values "
f"({len(data)}) "
"does not match length of index "
ValueError: Length of values (1) does not match length of index (7)
에러 메시지의 가장 아랫 줄에 이유가 보입니다. 넣은 데이터 model.coef_의 길이는 1인데, 인덱스 X.columns의 길이는 7이라서 안 된다는 겁니다. 즉 X.columns로 7개 값을 입력한다고 지정했으니, model.coef_ 길이가 7이어야 하는 겁니다.
💡리스트 길이에 대해서 다시 한번 생각해보기_예를 들어 [1, 2, 3, 4, 5] 의 길이는 5가 됩니다. 하지만 [ [ 1, 2, 3, 4, 5]]는 1이됩니다. 겉에 있는 [ ]가 하나의 리스트를 만들고 그 안에는 리스트가 있기 때문입니다. 만약 [[1, 2, 3], [4, 5]]라는 리스트가 있다면 길이가 얼마일까요? [1, 2, 3]과 [4, 5] 두 값이 들어 있으므로 2가 됩니다. array나 list의 길이를 len( ) 함수로 확인할 수 있습니다. 이미 답을 알고 있지만 len( ) 함수를 사용해 model.coef_의 길이를 더 확인하겠습니다.
len(model.coef_)
1
에러를 피하려면 어떤 방법을 쓰면 될까요? model.coef_ 길이와 X.columns값을 똑같이 맞추면 됩니다. model.coef의 길이가 1이므로 2중으로 씌워진 리스트 안에 있는 리스트를 콕 지정하면 됩니다. 여기서는 첫 번째 값을 인덱싱하면 되는 거죠.
len(model.coef_[0]) # 첫 번째 값의 길이 출력
7
[0]으로 인덱싱해주어 원하는 형태를 얻었습니다. 원하는 형태를 얻었으니, Series( )로 계수를 확인하겠습니다.
pd.Series(model.coef_[0], index = X.columns)
# model.coef_를 7개 값이 되도록 풀어서 컬럼 이름을 매핑
Pclass -1.182227
Age -0.039928
SibSp -0.321365
Parch 0.007964
Sex_male -2.568685
Embarked_Q -0.078995
Embarked_S -0.235632
dtype: float64
Parch를 제외하고는 모두 음수입니다. 목푯값인 survived가 1이면 생존이고, 0이면 사망이라는 점을 유념하고 변수들의 영향을 해석하겠습니다. 우선 Pclass는 음의 계수를 가지고 있기 때문에 Pclass가 높을수록 생존 가능성이 낮습니다. Pclass는 낮은 숫자일수록 비행기의 퍼스트 클래스처럼 더 비싼 티켓이기 때문에 더 유리하게 작용하지 않았을까 추측해볼 수 있습니다. Age는 낮을수록, 성별은 여성이 생존 가능성이 높습니다. 이미 우리가 알고 있는 타이타닉 이야기와 비슷합니다.
로지스틱 회귀 분석에서는 계수를 단순하게 기울기 값처럼 곱하여 수식을 만들어서는 안 됩니다. 이는 로지스틱 회귀 분석이 선형 회귀 분석에서 한 단계 계산을 더 거치기 때문인데요, 이 부분은 3편에서 자세히 설명하겠습니다.
다음편에서 계속 됩니다.

삼성전자에 마케팅 직군으로 입사하여 앱스토어 결제 데이터를 운영 및 관리했습니다. 데이터에 관심이 생겨 미국으로 유학을 떠나 지금은 모바일 서비스 업체 IDT에서 데이터 사이언티스트로 일합니다. 문과 출신이 미국 현지 데이터 사이언티스트가 되기까지 파이썬과 머신러닝을 배우며 많은 시행착오를 겪었습니다. 제가 겪었던 시행착오를 덜어드리고, 머신러닝에 대한 재미를 전달하고자 유튜버로 활동하고 책을 집필합니다.
현) IDT Corporation (미국 모바일 서비스 업체) 데이터 사이언티스트
전) 콜롬비아 대학교, Machine Learning Tutor, 대학원생 대상
전) 콜롬비아 대학교, Big Data Immersion Program Teaching Assistant
전) 콜롬비아 대학교, M.S. in Applied Analytics
전) 삼성전자 무선사업부, 스마트폰 데이터 분석가
전) 삼성전자 무선사업부, 모바일앱 스토어 데이터 관리 및 운영
강의 : 패스트캠퍼스 〈파이썬을 활용한 이커머스 데이터 분석 입문〉
SNS : www.youtube.com/c/데싸노트

