
딥러닝(Deep Learning)이 무엇인지, 어떤 기법이 있는지 알아보고 나서 파이토치(PyTorch) 기본 코딩 스타일을 알아봅니다. 이어서 딥러닝을 수행하는 프로세스와 최소한의 통계 지식, 시각화 기법을 알아봅니다. 빠르게 딥러닝을 알아가는 시간이 될 겁니다.
딥러닝 입문은 총 3개 장입니다. 1장에서 딥러닝 한눈에 살펴보기, 2장에서 인공 신경망 ANN 이해하기, 3장에서 간단한 신경망 만들기를 학습합니다.
간단한 신경망 만들기 ❶
가중치를 이용해 학습하는 신경망을 어떻게 만드는지 사인 함수 예측, 보스턴 집값 예측(회귀 분석), 손글씨 분류(다중분류) 신경망을 만들며 알아봅시다. 이번 장에서는 신경망의 동작뿐 아니라, 실제로 오차를 계산하고 직접 역전파해 가중치를 수정합니다. 또한 이전에 등장하지 않았던 손실 함수인 평균 제곱 오차와 크로스 엔트로피 오차에 대해서 설명합니다.
3장 간단한 신경망 만들기는 총 3편입니다.
핵심 용어 미리보기
- 파이토치에서 모듈은 신경망을 구성하는 기본 객체입니다. 모듈에는 구성요소를 정의하는 init( ) 함수와 순전파의 동작을 정의하는 forward( ) 함수가 있습니다.
- 간단한 신경망은 nn.Sequential, 복잡한 신경망은 nn.Module을 이용합니다.
- MSE(평균 제곱 오차)는 값의 차이의 제곱의 평균, CE(크로스 엔트로피)는 두 확률 분포의 차이입 니다. 회귀는 MSE, 분류는 CE 손실을 이용합니다.
- 다중분류는 신경망의 입력을 여러 범주로 분류하는 알고리즘입니다.
- 피처는 신경망의 입력으로 들어오는 값으로 데이터가 갖고 있는 특징입니다. 말그대로 특징으로 도 부릅니다.
- 배치는 데이터셋의 일부로 신경망의 입력으로 들어가는 단위, 에포크는 전체 데이터를 모두 한 번씩 사용했을 때의 단위입니다. 이터레이션은 하나의 에포크에 들어 있는 배치 수입니다.
- 최적화 알고리즘은 역전파된 기울기를 이용해 가중치를 수정합니다. Adam은 모멘텀과 RMSprop을 섞어놓은 가장 흔하게 사용되는 최적화 알고리즘입니다. 모멘텀은 기울기를 계산할 때 관성을 고려하는 것이고, RMSprop은 이동평균을 이용해 이전 기울기보다 현재의 기울기에 더 가중치를 두는 알고리즘입니다.
파이토치의 인공 신경망
파이토치는 딥러닝에 사용되는 대부분의 신경망을 torch.nn 모듈에 모아놨습니다. 앞에서 딥러닝은 신경망 층을 깊게 쌓아올린다고 말씀드렸는데, 파이토치도 여러 층을 쌓아서 딥러닝 모델을 만듭니다. 층(Layer)은 nn.Module 객체를 상속받아 정의되고, 층이 쌓이면 딥러닝 모델이 완성되는 것이죠. 프로그래밍 초보자라면 ‘객체를 상속받는다’는 말이 지금은 조금 어려울 수 있는데, nn.Module의 모든 구성요소를 복사해오는 거다’라고 생각하면 됩니다. 부모의 재산을 자식이 그대로 물려받는 것처럼요.
💡모델: 딥러닝에서는 인공 신경망과 같은 의미입니다. 일반적으로 딥러닝 신경망을 줄여서 딥러닝 모델이라고 부릅니다.
미리 설치합니다
!pip install sklearn
!pip install pandas
!pip install tqdm
1. 사인 함수 예측하기
흔히 딥러닝이라고 부르는 모델은 가중치를 몇 개나 갖고 있을까요? 백만 개 정도 가질까요? 놀랍게도 이미지를 인식하는 모델은 천만에서 1억 개가 넘는 가중치를 갖습니다. 자연스러운 문장을 생성하는 언어 모델인 OpenAI GPT-3는 1,750억 개까지 늘어난다고 합니다. 생각보다 많죠? 가중치의 의미를 간단히 말하자면 ‘1,750억 차 방정식을 풀어야 된다’는 뜻입니다.
걷지도 못하는 아이가 뛸 수 없는 노릇입니다. 1,750억 차 방정식이 있는 복잡한 모델을 지금 당장은 만들 수 없습니다. 차근차근 간단한 모델 먼저 배워봅시다. 그런 의미에서 고교 시절부터 인연이 깊은 삼각함수, 그중에서 제일 친숙한 사인곡선을 근사하는 3차 다항식의 계수를 인공 신경망을 이용해 구하겠습니다(계수가 곧 가중치입니다). 이번에는 3차 다항식을 이용하기 때문에 파라미터를 4개만 사용하지만 이후 소개할 모델들은 수백만 개, 혹은 그 이상의 파라미터를 포함합니다. 얼마나 정확하게 근사할지 벌써부터 기대되네요.
▼ 실습 예제 소개
파이토치로 학습을 할 때는 크게 두 가지를 신경 써야 합니다. 첫째는 우리가 학습시키고자 하는 모델이고, 나머지 하나는 모델의 학습 방식을 정하는 학습 루프입니다.
이제부터 사인곡선을 근사하는 딥러닝 신경망을 라이브러리를 사용하지 않고 직접 작성하겠습니다. 이 신경망은 다음과 같은 순서로 학습합니다.
▼ 파이토치의 학습 과정
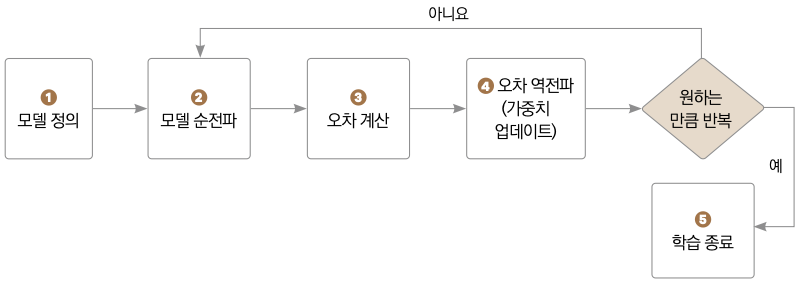
❶ 먼저 딥러닝 모델을 정의합니다. 모델을 학습하기 위해 데이터를 불러온 다음, 원하는 만큼 반복해서 모델을 학습합니다. ❷ 불러온 데이터를 이용해 모델의 예측값을 계산합니다. 이때 데이터가 입력층에서 출력층까지 흘러가기 때문에 이 계산을 모델의 순전파를 계산한다고 합니다. ❸ 모델의 예측값과 손실 함수를 이용해 오차를 계산합니다. ❹ 오차를 역전파하고 모델의 가중치를 수정합니다. ❺ 원하는 만큼 반복했다면 학습을 종료합니다.
1.1 랜덤하게 가중치를 적용해 사인곡선 그리기
사인곡선 공식은 y= sin(x) 입니다. x에 대해서 y값을 예측하는 모델을 만들어봅시다. 여기서는 랜덤하게 가중치를 뽑아 사인곡선을 근사하겠습니다. 사인함수는 3차 다항식으로 근사할 수 있습니다. 3차 다항식에는 계수가 4개 존재하므로 4개의 랜덤한 가중치를 뽑아 다항식의 계수로 이용하겠습니다.
💡Note: 3차 다항식에 계수가 4개인 이유: 3차 다항식은 최고차항의 계수가 3인 다항식입니다. 따라서 3차항부터 상수항까지 계수가 총 4개입니다.
실제 sin(x) 함수에서 추출한 y값으로 사인곡선을 그리는 그래프와, 임의의 가중치를 얻어 예측한 사인곡선 그래프를 출력하는 코드를 구현하겠습니다.
▼ 학습하기 전 사인 함수 모델
# 필요한 라이브러리 불러오기
import math # 수학 패키지 임포트
import torch # 파이토치 모듈 임포트
import matplotlib.pyplot as plt # 시각화 라이브로 matplotlib 임포트
# ❶ -pi부터 pi 사이에서 점을 1,000개 추출
x = torch.linspace(-math.pi, math.pi, 1000)
# ❷ 실제 사인곡선에서 추출한 값으로 y 만들기
y = torch.sin(x)
# ❸ 예측 사인곡선에 사용할 임의의 가중치(계수)를 뽑아 y 만들기
a = torch.randn(())
b = torch.randn(())
c = torch.randn(())
d = torch.randn(())
# 사인 함수를 근사할 3차 다항식 정의
y_random = a * x**3 + b * x**2 + c * x + d
# ❹ 실제 사인곡선을 실제 y값으로 만들기
plt.subplot(2, 1, 1)
plt.title("y true")
plt.plot(x, y)
# ❺ 예측 사인곡선을 임의의 가중치로 만든 y값으로 만들기
plt.subplot(2, 1, 2)
plt.title("y pred")
plt.plot(x, y_random)
# ❻ 실제와 예측 사인곡선 출력하기
plt.show()
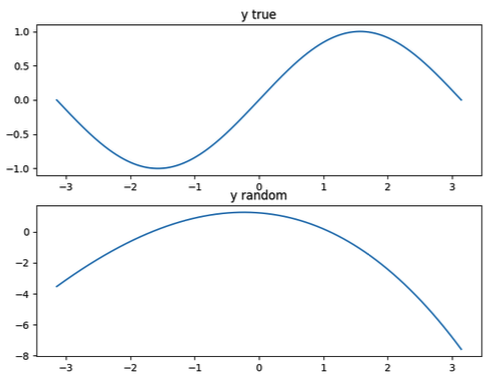
위의 그래프가 실제 사인함수이고, 아래 그래프는 임의의 가중치로 근사한 사인함수입니다. 아직은 가중치들을 학습하기 전이라 완전히 다른 모양의 그래프가 그려졌습니다. 또, 계수들은 랜덤하게 주어진 값이기 때문에 위에 나온 그림하고 다른 그림이 나와도 당황하지 마세요. 코드를 상세히 살펴보겠습니다.
❶ −π부터 π까지 1,000개의 점을 추출합니다.
▼ 새로 등장한 함수

❷ 실제 사인곡선에서 y 데이터를 입력합니다.
▼ 새로 등장한 함수

❸ 예측 사인곡선에 사용할 임의의 가중치를 뽑아 y를 만듭니다. 가중치로 사용할 3차 다항식의 계수는 4개(0차부터 3차까지)입니다. 계수 모두에 임의의 값을 넣어줍니다. 이때 사용한 torch.randn( ) 함수는 정규분포에 따라 랜덤하게 값을 반환해줍니다.
▼ 새로 등장한 함수

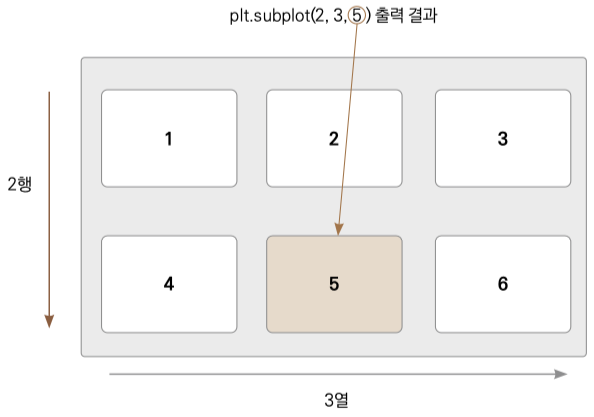
❹ 실제 사인곡선을 실제 y값으로 만듭니다. subplot( ) 함수는 여러 개의 그래프를 그려줍니다. 그중에서 실제의 y값을 그려줍니다. title( ) 함수로 각 그래프에 이름을 지정해주고, plot( ) 함수를 이용해 그래프의 입력값과 함수값을 지정해 그래프를 그립니다. subplot( ) 함수에 인수 3개를 주었습니다. 각각 행의 개수, 열의 개수, 위치를 뜻합니다. 예를 들어 subplot(2, 3, 5)는 2행 3열로 영역을 나누고 5번 위치에 그림을 그립니다. 다음 그림을 보면 이해가 될 겁니다.
▼ subplot이 그래프를 그리는 원리
▼ 새로 등장한 함수

❺ 예측 사인곡선을 만듭니다. 임의의 가중치로 만든 예측용 y값을 사용합니다.
❻ show( ) 함수로 그래프를 그려줍니다.
▼ 새로 등장한 함수

1.2 가중치를 학습시켜서 사인곡선 그리기
드디어 딥러닝의 첫 단추인 가중치를 학습할 차례입니다. 이번에는 사인곡선을 신경망으로 학습해서 근사해보겠습니다. 사인 곡선과 상당히 비슷한 곡선이 그려질 것 같네요.
달라진 코드를 쉽게 확인할 수 있게 배경을 진하게 처리해뒀습니다. 먼저 각 계수에 대한 기울기를 계산합니다. 기울기를 계산한 다음, 학습률과 기울기를 곱해 보폭을 얻습니다. 이때 얻은 보폭만큼 계수들을 수정하면 됩니다.
▼ 학습 전후 비교해보기
learning_rate = 1e-6 # 학습률 정의
# 학습 2,000번 진행
for epoch in range(2000):
y_pred = a * x**3 + b * x**2 + c * x + d
loss = (y_pred - y).pow(2).sum().item() # ❶ 손실 정의
if epoch % 100 == 0:
print(f"epoch{epoch+1} loss:{loss}")
grad_y_pred = 2.0 * (y_pred - y) # ❷ 기울기의 미분값
grad_a = (grad_y_pred * x ** 3).sum()
grad_b = (grad_y_pred * x ** 2).sum()
grad_c = (grad_y_pred * x).sum()
grad_d = grad_y_pred.sum()
a -= learning_rate * grad_a # ❸ 가중치 업데이트
b -= learning_rate * grad_b
c -= learning_rate * grad_c
d -= learning_rate * grad_d
# 실제 사인 곡선을 그리기
plt.subplot(3, 1, 1)
plt.title("y true")
plt.plot(x, y)
# 예측한 가중치의 사인 곡선을 그리기
plt.subplot(3, 1, 2)
plt.title("y pred")
plt.plot(x, y_pred)
# 랜덤한 가중치의 사인 곡선 그리기
plt.subplot(3, 1, 3)
plt.plot(y_random)
plt.title("y random")
# 실제로 그래프 출력하기
plt.show()
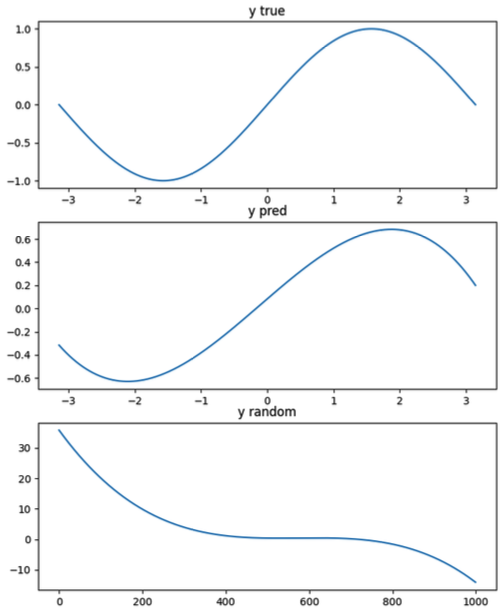
첫 번째 그래프가 진짜 사인곡선이고 두 번째 그래프는 사인곡선을 학습한 결과를 가지고 만든 그래프입니다. 두 그래프가 거의 비슷해졌습니다. 마지막 그래프는 학습이 이루어지기 전의 그래프입니다. 사인곡선과는 완전히 달랐던 그래프가 몇 번의 학습을 거친 것만으로도 사인곡선과 유사하게 변한 것을 알 수 있습니다.
이전 코드와 달라진 부분만 설명하겠습니다. ❶ 손실을 정의합니다. 흔히 사용하는 제곱오차, pow(2)는 제곱을, sum( )은 합, item( )은 실수값으로 반환하라는 뜻입니다. ❷ 가중치를 업데이트하는 데 사용되는 손실값을 미분했습니다. ❸ 가중치는 기울기의 반대 방향으로 움직입니다. 만약 기울기가 양수라면 빼주고, 음수라면 더해줘야 하므로 기울기에 -1을 곱해줍시다.
여기서는 a, b, c, d 총 4개의 가중치(계수)를 사용했습니다. 하지만 자연어 처리에서는 가중치를 1,750억 개 정도 사용한다고 말씀드렸습니다. 따라서 이런 식으로 수백만 개의 가중치를 일일이 계산하는 일은 불가능합니다. 우리는 선배들이 닦아놓은 길을 걸어가면 됩니다. 다음 절부터는 복잡한 가중치 계산을 파이토치에 맡겨보겠습니다.
다음편에서 계속 됩니다.

책 내용 중 궁금한 점, 공부하다가 막힌 문제 등 개발 관련 질문이 있으시다면
언제나 열려있는 <[Must Have] 텐초의 파이토치 딥러닝 특강> 저자님의
카카오채널로 질문해주세요!


