
딥러닝(Deep Learning)이 무엇인지, 어떤 기법이 있는지 알아보고 나서 파이토치(PyTorch) 기본 코딩 스타일을 알아봅니다. 이어서 딥러닝을 수행하는 프로세스와 최소한의 통계 지식, 시각화 기법을 알아봅니다. 빠르게 딥러닝을 알아가는 시간이 될 겁니다.
딥러닝 입문은 총 3개 장입니다. 1장에서 딥러닝 한눈에 살펴보기, 2장에서 인공 신경망 ANN 이해하기, 3장에서 간단한 신경망 만들기를 학습합니다.
인공 신경망 ANN 이해하기 ❸
인공 신경망을 이용한 딥러닝 기초 지식을 설명합니다. 먼저 인공 신경망이 어떻게 동작하는지, 어떻게 발전해왔는지 알아봅시다. 그다음은 신경망끼리 비교해 어떤 신경망이 더 좋은 성능을 갖고 있는지 성능을 비교하는 방법을 알아봅시다. 마지막으로 인공지능이 어떤 방식으로 학습하는지를 알아보겠습니다.
2장 인공 신경망 ANN 이해하기는 총 3편입니다.
6. 활성화 함수로 기울기 소실 예방하기
오차가 역전파될 때 층을 한 번 거칠 때마다 시그모이드의 도함수가 곱해집니다. 하지만 시그모이드의 도함수는 최댓값이 0.25이기 때문에 곱해질 때마다 오차가 점점 줄어들게 됩니다. 즉, 층이 너무 깊어지면 출력층에 가까운 은닉층들은 제대로 학습이 이루어지나, 입력층에 가까운 은닉층들은 제대로 학습이 이루어지지 않습니다.
또한, 시그모이드 함수는 실수 전체를 0과 1 사이의 값으로 압축하게 됩니다. 시그모이드 도함수의 그래프를 보면 z의 크기가 커지면 도함수의 값이 0에 가까워지는 것을 볼 수 있습니다. 이렇게 기울기 크기가 0에 가까워지는 현상을 기울기 소실 문제라 부릅니다.
▼ 시그모이드 함수의 도함수
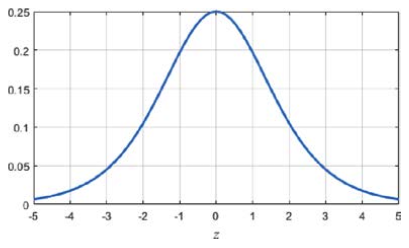
기울기 소실 문제를 해결하려면 미분해도 값이 줄어들지 않는 활성화 함수가 필요합니다.
다음은 ReLU(Rectified Linear Unit, 렐루) 함수의 그래프입니다.
▼ ReLU 함수
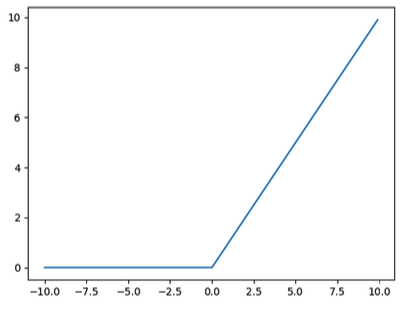
ReLU 함수는 0보다 작은 값을 0으로 반환하고 0보다 큰 값은 들어온 값 그대로 내보냅니다. ReLU 함수를 미분하면 0보다 큰 범위에서 기울기 1을 갖기 때문에 기울기 소실 문제가 발생하지 않습니다. 하지만 0보다 작은 범위에서는 0을 반환하기 때문에 그 뉴런과 연결되어 있는 다음 층의 뉴런은 입력의 일부가 0이 됩니다. 다음 층으로 들어가는 입력이 0이라는 것은 넘어가는 정보가 없어진다는 뜻이기도 합니다. 즉, 우리가 원하는 동작은 아닙니다. 따라서 딥러닝 모델을 만들 때는 은닉층의 깊이, 활성화 함수, 손실 함수 등을 복합적으로 고려해야 합니다.
시그모이드와 ReLU 외에도 다양한 활성화 함수가 있습니다. 자주 사용하는 소프트맥스 함수까지 3가지 활성화 함수를 표로 정리해두었으니 참고 바랍니다.
▼ 활성화 함수
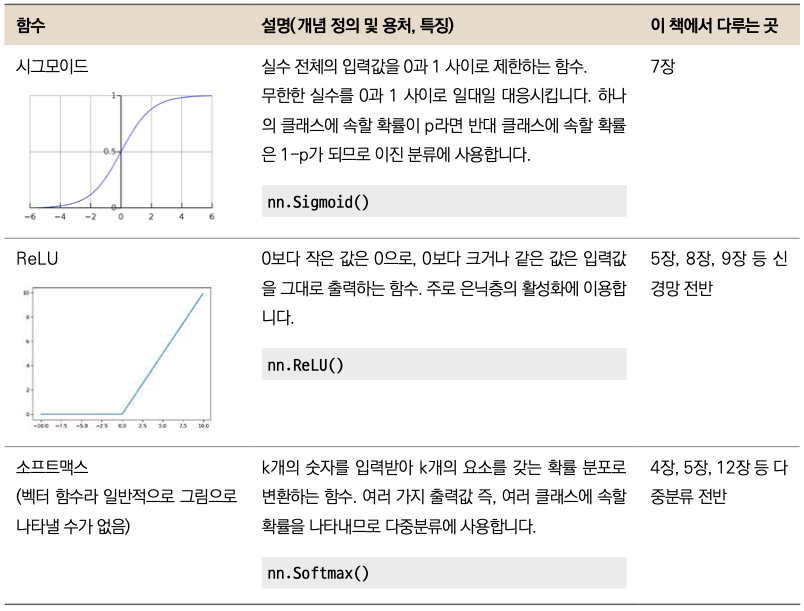
7. 신경망 성능 비교하기
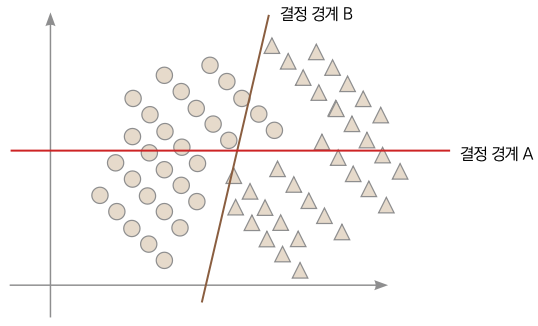
이제 손실 함수를 최소화하는 직선으로 신경망을 이용해 데이터를 분류할 수 있게 되었습니다. 그렇다면 손실 함수 값은 작으면 작을수록 좋은 것일까요? 다음과 같은 데이터 분포를 분류하는 두 결정 경계를 봅시다.
▼ 같은 데이터를 다르게 분류하는 두 결정 경계
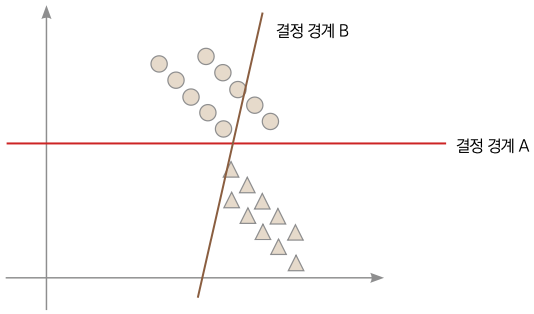
앞의 그림과 같은 학습용 데이터가 있다고 가정해봅시다. 결정 경계 A는 완벽하게 동그라미와 세모를 분류합니다. 반면 결정 경계 B는 완벽하게 분류하지 못합니다. 그렇다면 A가 B보다 좋은 결정 경계일까요? 손실 함수 값도 분명 B보다 A가 작을 텐데 말입니다. 이제 데이터를 조금 더 모아보겠습니다.
▼ 오버피팅된 결정 경계
💡오버피팅(Overfitting): 갖고 있는 데이터에 대해 너무 완벽하게 최적화된 학습을 의미합니다. 학습에 사용하지 않은 데이터에 대해서 예측 성능이 더 떨어지는 경우가 많습니다. 우리말로 과적합이라고도 부릅니다.
데이터가 조금 더 모였습니다. 이제는 A보다 B가 더 잘 분류하는 결정 경계가 되었군요. 이처럼 학습용 데이터를 완벽하게 분류할 수 있다고 해서 반드시 성능이 좋은 결정 경계라고 할 수는 없습니다. 학습용 데이터를 너무 완벽하게 분류할 수 있는 상황을 ‘오버피팅’이라고 부릅니다(학습용 데이터에만 최적화된 상황). 학습용 데이터에 대해 어느 정도
오차를 갖고 있어야 아직 관측되지 않은 데이터에 대한 성능을 확보할 수 있습니다. 그렇다면 아직 관측되지 않은 데이터를 이용한 결정 경계의 성능 평가는 어떻게 할까요? 정답을 갖고 있는 데이터의 일부분을 평가용으로 남겨두는 겁니다(평가용 데이터는 모델 학습에 사용하지 않습니다). 학습에 이용한 데이터를 학습용 데이터(Training Data), 신경망의 성능 평가에 사용한 데이터를 평가용 데이터(Test Data)라고 부릅니다. 평가용 데이터에 대한 성능도 마찬가지로 모든 경우 수를 고려한 데이터가 아니기 때문에 맹신은 금물입니다만, 학습 당시 이용되지 않은 데이터에 대한 성능이므로, 관측되지 않은 데이터에 대한 성능을 간접적으로 나타냅니다. 이렇게 신경망의 학습은 학습용 데이터와 평가용 데이터를 이용해 성능을 확인합니다.
평가용 데이터는 학습에 이용하지 않습니다. 그렇기 때문에 학습이 종료될 때까지 평가용 데이터에 대한 성능을 확인하기 어렵습니다. 학습용 데이터의 일부를 고의적으로 학습에 이용하지 않고 중간 평가에 사용하는 데이터를 검증용 데이터(Validation Data)라고 부릅니다. 이 책에서는 학습용 데이터양을 확보하기 위해 검증용 데이터를 사용하지 않고, 전부 학습에 사용합니다.
ANN 이해하기 마무리
딥러닝 기초 지식을 배웠습니다. 인공 신경망은 들어온 입력에 가중치를 곱한 다음 편향을 더해, 활성화 함수의 입력으로 사용하는 알고리즘입니다. 뉴런이 하나인 단층 신경망은 분류하지 못하는 데이터의 분포가 있지만, 뉴런을 여러 개 갖는 다층 신경망을 이용하면 분류할 수 있습니다.
인공 신경망의 성능은 손실 함수를 이용해 비교할 수 있습니다. 손실이 적을수록 좋은 신경망이라고 볼 수 있습니다. 하지만 학습용 데이터를 완벽하게 분류하는 것은 오버피팅이 되므로 조금의 오차는 있는 것이 좋았습니다. 손실을 줄이기 위해서 경사 하강법을 이용해 오차 역전파를 진행합니다. 경사 하강법은 출력층부터 입력층까지 미분한 값들을 점점 곱해가면서 가중치를 수정합니다. 하지만 활성화 함수로 이용하는 시그모이드 함수의 도함수는 최댓값이 0.25로 곱할수록 점점 기울기가 줄어들게 됩니다. 이걸 해결하기 위해 ReLU 함수를 이용했습니다.
딥러닝은 결과를 해석하는 일은 쉽지 않습니다. 똑같은 코드를 누가 실행하느냐에 따라 결과가 바뀌고, 성능이 좋게 나오면 운이 좋아서 그런 건지, 아니면 지금 데이터에 한해서만 성능이 좋은 건지 알기 어렵습니다. 이 책을 통해 여러 딥러닝 신경망을 만들며 실력을 갈고 닦으면 여러분만의 해석이 가능해지게 될 겁니다.
2장 인공 신경망 ANN 이해하기가 끝났습니다. 딥러닝 입문 3장 간단한 신경망 만들기에서는 간단한 신경망을 만들어 봅시다.

책 내용 중 궁금한 점, 공부하다가 막힌 문제 등 개발 관련 질문이 있으시다면
언제나 열려있는 <[Must Have] 텐초의 파이토치 딥러닝 특강> 저자님의
카카오채널로 질문해주세요!


