
딥러닝(Deep Learning)이 무엇인지, 어떤 기법이 있는지 알아보고 나서 파이토치(PyTorch) 기본 코딩 스타일을 알아봅니다. 이어서 딥러닝을 수행하는 프로세스와 최소한의 통계 지식, 시각화 기법을 알아봅니다. 빠르게 딥러닝을 알아가는 시간이 될 겁니다.
딥러닝 입문은 총 3개 장입니다. 1장에서 딥러닝 한눈에 살펴보기, 2장에서 인공 신경망 ANN 이해하기, 3장에서 간단한 신경망 만들기를 학습합니다.
인공 신경망 ANN 이해하기 ❶
인공 신경망을 이용한 딥러닝 기초 지식을 설명합니다. 먼저 인공 신경망이 어떻게 동작하는지, 어떻게 발전해왔는지 알아봅시다. 그다음은 신경망끼리 비교해 어떤 신경망이 더 좋은 성능을 갖고 있는지 성능을 비교하는 방법을 알아봅시다. 마지막으로 인공지능이 어떤 방식으로 학습하는지를 알아보겠습니다.
2장 인공 신경망 ANN 이해하기는 총 3편입니다.
핵심 용어 미리보기
- 인공 뉴런(퍼셉트론)은 입력값과 가중치, 편향을 이용해 출력값을 내는 수학적 모델입니다.
- 단층 인공 신경망은 퍼셉트론을 하나만 사용하는 인공 신경망입니다.
- 다층 인공 신경망은 퍼셉트론을 여러 개 사용하는 인공 신경망입니다.
- 입력값을 표현하는 입력층, 신경망의 출력을 계산하는 출력층, 입력층 이후부터 출력층 전까지는 은닉층입니다.
- 가중치는 입력의 중요도를 나타내고 편향은 활성화의 경계가 원점으로부터 얼마나 이동할지를 결정합니다.
- 활성화 함수는 해당 뉴런의 출력을 다음 뉴런으로 넘길지를 결정합니다. 시그모이드 함수는 뉴런 의 출력값을 0과 1 사이로 고정합니다.
- 손실 함수는 정답과 신경망의 예측의 차이를 나타내는 함수입니다.
- 경사 하강법은 손실을 가중치에 대해 미분한 다음, 기울기의 반대 방향으로 학습률만큼 이동시키 는 알고리즘입니다.
- 오차 역전파는 올바른 가중치를 찾기 위해 오차를 출력층으로부터 입력층까지 전파하는 방식입 니다.
- 오버피팅은 과적합이라고도 합니다. 학습에 사용한 데이터에 최적화되게 학습되어서 다른 데이 터에 대한 예측 성능이 떨어지는 경우를 의미합니다.
- 기울기 소실은 출력층으로부터 멀어질수록 역전파되는 오차가 0에 가까워지는 현상입니다.
1. 퍼셉트론
인공 신경망(Artificial Neural Network, ANN)은 사람의 신경망을 본떠서 만든 알고리즘입니다. 가장 처음 등장한 인공 신경망은 1943년 워렌 스터기스 맥컬록(Warren Sturgis McCulloch)과 월터 피츠(Walter Pitts)가 만든 퍼셉트론(Perceptron)입니다. 퍼셉트론은 인공 뉴런을 뜻하며, 사람의 뇌세포(뉴런)를 수학적으로 표현한 겁니다. 인공 신경망은 퍼셉트론, 즉 인공 뉴런의 집합체로 하나의 뉴런이 존재하면 단층 신경망, 여럿을 조합하면 다층 신경망이라고 부릅니다. 퍼셉트론의 동작 과정을 자세히 알아봅시다.
💡퍼셉트론, 인공 뉴런, 인공 신경망: 퍼셉트론, 혹은 인공 뉴런은 인간의 뇌세포를 수학적으로 표현한 알고리즘입니다. 퍼셉트론을 이용해 만든 모든 구조물을 인공 신경망이라고 부릅니다. 퍼셉트론을 하나만 사용하면 단층 신경망, 여러 개 사용하면 다층 신경망이라고 부릅니다.
▼ 한눈에 보는 퍼셉트론 동작 원리
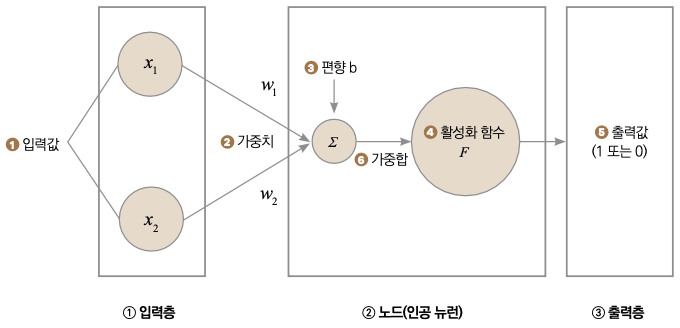
퍼셉트론은 ① 입력층, ② 노드(인공 뉴런), ③ 출력층으로 구성됩니다. 뇌세포는 다른 뇌세포로부터 일정 강도 이상(임곗값)의 자극(입력)을 받지 않으면 다음 뇌세포로 정보를 전달하지 않습니다. 인공 신경망 역시 입력값에 가중치를 곱해 더해준 다음, 활성화 함수를 이용해 다음 노드에 정보를 전달할지 말지를 결정합니다. 가중치는 중요한 입력값을 더 키우고, 중요하지 않은 입력값을 줄이는 등, 입력에 대한 중요도를 나타내는 숫자입니다. 그림에서 보면 ❶ 입력값( x1, x2)에 대응하는 ❷ 가중치(w1, w2)가 각각 곱해진 다음, ❹ 활성화 함수(F)의 입력으로 사용되었습니다. 이때 더해지는 ❸ 편향은 활성화 함수의 임곗값을 이동시키는 역할을 합니다. 활성화를 거친 후 얻어지는 값을 ❺ 출력값이라고 부릅니다. ❻ 또한 입력값과 가중치를 곱해서 얻은 가중합이 활성화 함수의 입력으로 사용됩니다.
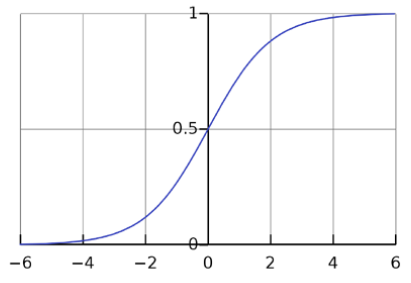
활성화 함수로는 시그모이드 함수(Sigmoid Function)를 사용합니다. 시그모이드 함수는 실수 전체의 모든 입력에 대해 출력이 0과 1 사이의 실수만을 갖게 됩니다. 시그모이드 함수를 사용하는 이유는 인공 신경망의 출력을 확률로써 다루고 싶기 때문입니다. 확률 또한 값이 0과 1 사이로 표현되기 때문에 활성화 함수로 시그모이드 함수를 이용합니다.
퍼셉트론의 출력값 y는 F(x1w 1 + x2 w2 + b)가 됩니다. 여기서 F(x1w 1 + x2 w2 + b)는 활성화 함수입니다. 여기서 가중합 a는 a = (x1w 1 + x2 w2 + b)로 표현됩니다.
▼ 시그모이드 함수
앞의 그림에서 사용한 입력값은 총 2개였습니다. 즉 y값은 x1과 x2로 표현할 수 있다는 뜻입니다. 가중치(w1, w2)는 변하는 값이 아니라 고정된 상수이므로, 뉴런의 가중합(a)을 그림으로 나타내면 다음과 같습니다.
▼ 입력값의 변화에 따른 가중합의 변화
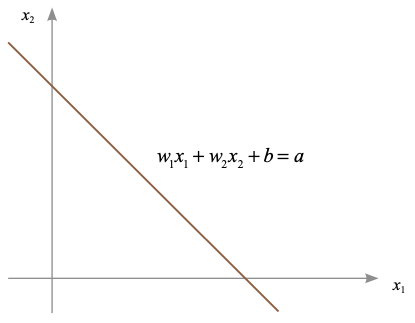
가중치가 변함에 따라 위 그래프에서 직선의 기울기와 위치가 변할 겁니다. 뉴런의 계산 결과인 a의 값에 의해 직선의 아래에 있는지 혹은 위에 있는지 결정을 내릴 수 있기 때문에 위와 같은 직선을 결정 경계라고도 부릅니다. 그럼 결정 경계를 이용해 어떤 문제를 해결할 수 있을까요? 다음과 같은 데이터가 주어져 있다고 합시다.
▼ 결정 경계를 이용한 데이터 분류의 예
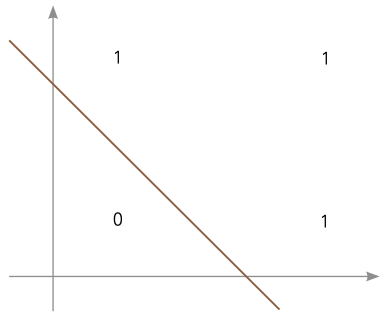
앞의 그림과 같은 데이터가 주어졌을 때 직선을 이용하면 0과 1을 구분할 수 있습니다. 적당한 가중치가 주어진다면 그림과 같은 결정 경계를 만들 수 있고, 입력에 따라 결정 경계의 값보다 크다면 1로, 작다면 0으로 구분할 수 있습니다. 또한 이 결정 경계를 만들기 위해 하나의 퍼셉트론을 이용했으므로 이런 구조를 단층 신경망이라고 부릅니다.
2. 다층 신경망으로 단층 신경망 한계 극복하기
단층 신경망은 다양한 형태의 데이터를 분류할 수 있습니다. 그러나 모든 형태의 데이터에 대해 분류할 수 있을까요? 아쉽지만 단층 신경망은 분류 가능한 데이터 형태보다 분류할 수 없는 데이터 형태가 더 많습니다. 다음과 같은 (단층 신경망으로 분류할 수 없는) 데이터의 분포를 생각해봅시다.
▼ 단층 신경망으로 분류할 수 없는 데이터의 예
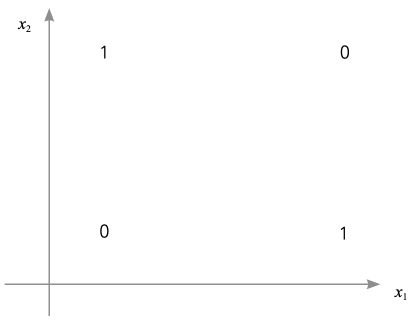
위와 같은 형태의 데이터를 XOR 데이터라고 부릅니다. 여기서 선을 하나 그어서 0과 1을 분류할 수 있을까요? 불가능합니다. XOR는 배타적 논리 연산, 즉 x1과 x2 중 하나만 1일 때 결과가 1인 경우를 말합니다. 1969년 마빈 민스키(Marvin Minsky)가 퍼셉트론이 XOR 문제를 풀 수 없다는 사실을 수학적으로 증명했습니다.
▼ XOR 진리표
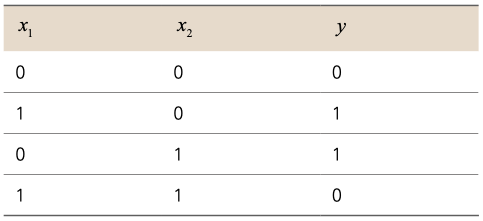
그래서 등장한 것이 바로 다층 신경망입니다. 단층 신경망이 하나의 직선을 이용해 데이터를 분류하는 반면, 다층 신경망은 선을 여러 번 그어서 데이터를 분류합니다. 이제 다층 신경망이 어떤 방식으로 데이터를 분류하는지 알아봅시다.
▼ 다층 신경망이 XOR 데이터를 분류하는 방법
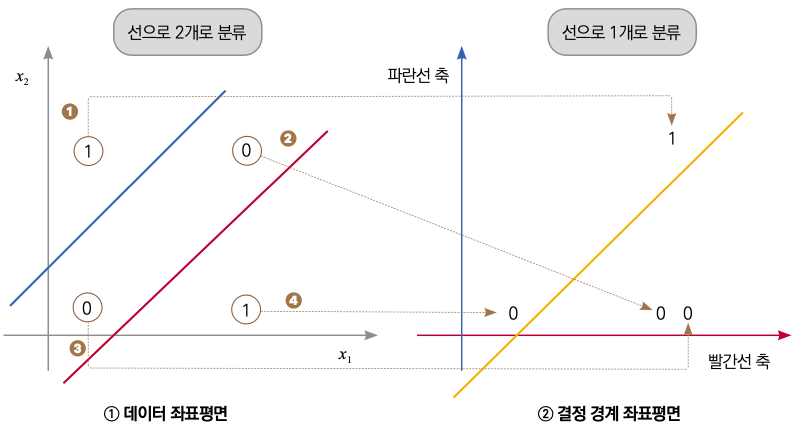
앞에서 직선 하나로는 XOR를 분류할 수 없다고 말씀드렸습니다. 그렇기 때문에 직선을 여러 개 사용하여 데이터를 분류해야 합니다.
다층 신경망이 직선을 사용해서 XOR 문제를 해결하려면, 직선 여러 개를 이용해 데이터의 분포를 바꿔줄 필요가 있습니다. 이를 기저 벡터 변환이라고 합니다. 기저 벡터를 변환하는다는 뜻은 좌표계에서 하나의 점을 표현하는 기준을 바꿔준다는 뜻입니다. 왼쪽 데이터 좌표평면에서는 x1과 x2가 기준입니다. 기준을 빨간선과 파란선으로 바꿔주면 데이터 좌표평면상의 모든 점이 결정 경계 좌표평면상(오른쪽)으로 이동하게 됩니다. 이런 과정을 여러 번 반복하는 것이 바로 다층 신경망이 데이터를 분류하는 방식입니다. 이제부터 간단하게 직선 2개를 이용해 분류가 가능한 분포를 만들어줄 겁니다.
먼저 두 직선(파란선과 빨간선)을 그어줍니다. 이 두 선은 각각이 결정 경계가 되어 선보다 위에 있는 값은 1을, 작은 값은 0을 반환한다고 가정합시다. ❹ 의 1이 빨간선 아래에 있다고 헷갈리지 마세요. 아직은 계산의 중간 단계에 있기 때문에 정답값은 고려하지 않아도 됩니다. 정답값은 모든 계산이 끝난 신경망의 최종 출력에서만 고려합니다.
두 좌표평면은 각각 축이 다르게 설정되어 있습니다. ① 데이터 좌표평면은 x1과 x2를 표현하는 축인 것에 반해, ② 결정 경계 좌표평면은 가로축이 빨간선의 결괏값, 세로축은 파란선의 결괏값을 나타내고 있습니다. ①번 좌표평면에 있는 점을 ②번 좌표평면으로 옮길 수 있다면 선 하나로도 1과 0을 구분지을 수 있습니다(1장에서 선은 ‘데이터를 표현하는 직선인 가설’이라고 말씀드렸습니다. 즉 다층 신경망도 마지막에 데이터를 분류하려면 선(가설)이 하나이어야 합니다). 왼쪽 좌표평면상의 점을 어떻게 오른쪽 좌표평면으로 이동시킬 수 있을까요?
먼저 1 위치에 있는 1을 보겠습니다. 데이터 좌표평면상의 점을 보면 파란선과 빨간선, 양쪽보다 위쪽에 위치해 있습니다. 따라서 결정 경계 좌표평면에 표시된 위치(결정 경계 좌표평면 상 (1, 1)의 위치)로 이동합니다. 2 와 3 위치에 있는 0을 보겠습니다. 데이터 좌표평면에 표시된 두 점 모두 파란선보다는 아래에, 빨간선보다는 위에 위치해 있습니다. 따라서 두 점 모두 결정 경계 좌표평면에 표시된 위치(결정 경계 좌표평면 상 (1, 0)의 위치)로 이동합니다. 마지막으로 4 위치에 있는 1을 보겠습니다. 데이터 좌표평면 상에 표시된 점은 파란선과 빨간선보다 아래에 위치해 있기 때문에 결정 경계 좌표평면 상에 표시된 위치(결정 경계 좌표평면 상 (0, 0)의 위치)로 이동합니다. 이제 결정 경계 좌표평면상의 0과 1의 위치를 살펴보면 그림과 같이 하나의 (노란색) 직선으로 구분할 수 있게 되었습니다. 이렇게 좌표를 바꾸는 것이 ‘기저 벡터 변환’입니다.
💡기저 벡터 변환: 좌표계에서 점을 표현하는 기준(기저 벡터)을 다른 벡터로 변환하는 기법
기저 벡터는 공간을 표현하는 벡터의 집합을 의미합니다. 즉, 데이터 좌표평면에서는 (x1, 0)과 (0, x2 )를 기저 벡터로 사용했다면, 결정 경계 좌표평면의 기저 벡터는 데이터 좌표평면에서의 빨간선과 파란선이 되는 겁니다. 빨간선과 파란선은 x1과 x2로 표현할 수 있기 때문에, 결정 경계 좌표평면상의 점도 x1과 x2로 표현할 수 있게 됩니다.
이처럼 직선 하나로 구분이 불가능한 데이터 분포도 직선을 여러 개 이용하면 구분할 수 있습니다. 직선 하나를 사용하면 단층 퍼셉트론single layer perceptron, 여러 층에 걸쳐 퍼셉트론이 분포되어 있으면 다층 퍼셉트론(MLPMulti Layer Perceptron)입니다. 비슷하게 하나의 층이 존재하는 신경망을 단층 신경망, 여러 층이 존재하는 신경망을 다층 신경망이라고 부릅니다. 퍼셉트론보다 신경망이 더 넓은 범위를 이르는 용어이므로 이후에는 구분 없이 ‘신경망’으로 부르겠습니다. 단층 신경망과 다층 신경망을 그림으로 알아보겠습니다.
▼ 단층 신경망과 다층 신경망의 구분
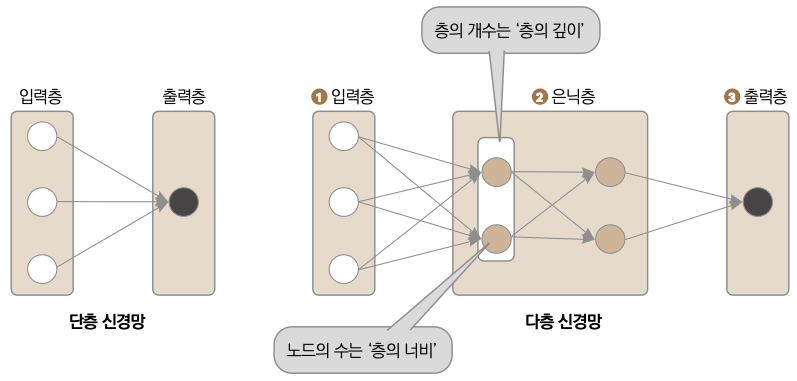
다층 신경망은 입력층, 은닉층, 출력층으로 구성됩니다. 1 입력층은 데이터가 들어오는 층입니다. 2 은닉층은 굳이 값을 알 필요가 없기 때문에 출력값을 숨긴다 해서 붙여진 이름입니다. 신경망의 하나의 층에서의 노드의 수를 ‘층의 너비’, 층의 개수를 ‘층의 깊이’라고 합니다. 3 출력층은 신경망 오른쪽으로 전달되는데, 이 방향으로 정보가 전달되는 것을 순전파라고 말합니다.
💡순전파(forward propagation): 데이터가 입력층으로부터 출력층까지 순서대로 전달되는 것을 의미합니다. 출력층의 출력을 계산할 때 순전파 결과와 역전파에 사용할 기울기도 계산합니다. 딥러닝이 메모리를 많이 사용하는 까닭은 가중치를 수정하는 데 사용하는 계산값을 모두 저장하기 때문입니다.
💡TIP: GPU 메모리가 부족할 때는 은닉층의 너비를 줄이는 것보다 은닉층의 깊이를 줄이는 것이 더 효과적일 수 있습니다. 계산 결과를 저장하는 데 가장 많은 메모리를 사용하기 때문입니다.
다음편에서 계속 됩니다.

책 내용 중 궁금한 점, 공부하다가 막힌 문제 등 개발 관련 질문이 있으시다면
언제나 열려있는 <[Must Have] 텐초의 파이토치 딥러닝 특강> 저자님의
카카오채널로 질문해주세요!


