
딥러닝(Deep Learning)이 무엇인지, 어떤 기법이 있는지 알아보고 나서 파이토치(PyTorch) 기본 코딩 스타일을 알아봅니다. 이어서 딥러닝을 수행하는 프로세스와 최소한의 통계 지식, 시각화 기법을 알아봅니다. 빠르게 딥러닝을 알아가는 시간이 될 겁니다.
딥러닝 입문은 총 3개 장입니다. 1장에서 딥러닝 한눈에 살펴보기, 2장에서 인공 신경망 ANN 이해하기, 3장에서 간단한 신경망 만들기를 학습합니다.
딥러닝 한눈에 살펴보기 ❶
핵심 용어 미리보기
- 머신러닝은 입력 데이터를 이용해 알지 못하는 변수를 반복적으로 학습해나가면서 예측하는 알 고리즘입니다.
- 딥러닝은 인공 신경망을 사용한 머신러닝 알고리즘입니다.
- 지도 학습은 데이터에 정답 데이터를 제공하는 학습 방법입니다.
- 비지도 학습은 데이터에 정답 데이터를 제공하지 않은 학습 방법입니다.
- 강화 학습은 데이터를 사용하지 않고, 인공지능이 스스로 시행착오를 겪으며 성장하는 학습 방법입니다.
- 딥러닝 문제 해결 프로세스는 ❶ 문제 정의 → ❷ 데이터 수집 → ❸ 데이터 가공 → ❹ 딥러닝 모델 설계 → ❺ 딥러닝 모델 학습 → ❻ 성능 평가 순서로 진행됩니다.
- 독립변수는 다른 변수의 값을 결정하는 변수를 말합니다. 입력값으로 사용됩니다.
- 종속변수는 독립변수에 의해 값이 결정되는 변수를 의미합니다. 출력 대상이 되는 변수(목푯값)입니다.
1. 머신러닝과 딥러닝
사람은 직접 경험하거나, 책이나 영상으로 타인의 경험을 간접 경험하면서 학습합니다. 누군가 “사람은 학습합니다”라고 말하면 별다른 의문 없이 “뭐 그렇지, 맞아”라고 수긍할 겁니다. 그렇다면 “기계가 학습한다”는 말의 의미는 무엇일까요?
먼저 기계에게 간접 체험을 시켜봅시다. 예를 들어 수많은 질병 증상을 기계에게 알려준 다음, 환자의 증상을 알려준다면 기계는 증상을 토대로 병을 진단할 겁니다. 열이 나고 목이 아프면서 기침을 한다면 감기라고 말이죠. 또 다른 예시를 하나 들어볼까요? 컴퓨터의 결함에 대한 증상을 컴퓨터에게 알려주고, 내 컴퓨터의 상황을 알려주면 어디가 고장이 났는지 알 수 있을 겁니다. 이렇게 특정 분야의 전문가처럼 동작하는 시스템을 전문가 시스템(Experts System)이라고 부릅니다. 최초의 전문가 시스템은 1960년 보건 분야 인공지능인 덴드랄입니다.
▼ 전문가 시스템의 예
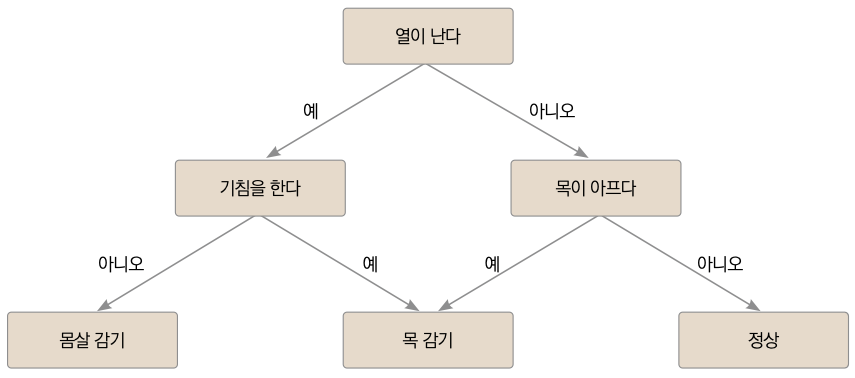
그러나 이런 전문가 시스템은 진정한 의미의 인공지능은 아니었습니다. if else 구문으로 다양한 경우의 수를 구현한 프로그램에 가까웠습니다. 인간이 입력한 지식 베이스(사례집)를 활용해 특정 분야에서 1980년대까지 상업적으로 사용되었지만, 미리 등록되지 않은 지식에 대해서는 알지 못해 1990년대에 들면서 퇴출되었습니다. 전문가 시스템에 어떤 문제점이 있을까요?
전문가 시스템의 가장 큰 약점은 시행착오가 없다는 겁니다. 사례집을 단순히 찾아볼 뿐, 무언가를 학습하는 것이 아니었다는 뜻입니다. 또한 기계의 힘을 빌려야 하는 복잡한 분야에 전문가 시스템을 이용하려면 계산량이 너무 많아졌습니다. 이런 문제를 해결하고자 기계에게 시행착오 개념을 알려주고, 문제를 간단하게 만들어 제공하기 시작했습니다. 대용량 데이터를 바탕으로 입력값에 대한 출력값을 예측하거나 범주로 나눌 수 있는 기계를 연구한 겁니다.
문제를 크게 값을 예측하는 회귀 문제, 범주로 나누는 분류 문제로 나눌 수 있습니다. 회귀 문제와 분류 문제는 맥락이 비슷합니다. 두 문제 모두 데이터를 수치화한 다음, 해당 데이터를 가장 잘 나타내는 직선(고차원에서는 결정 경계 또는 초평면이라고 부름)을 구하고 나서 직선 위에 있는지, 아래에 있는지를 기준으로 범주를 나누면 되기 때문입니다.
▼ 결정 경계의 시각적 이해
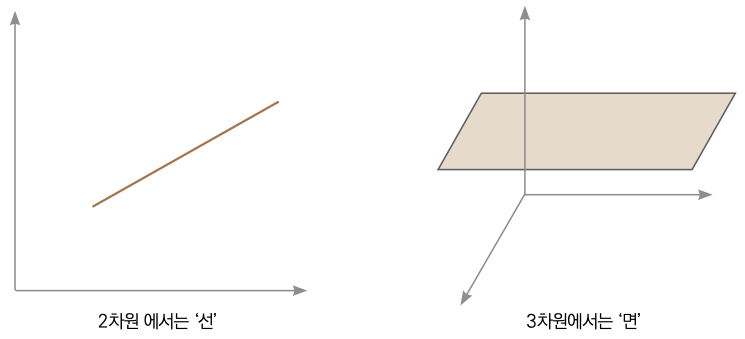
앞의 그림에서 선을 ‘데이터를 표현하는 직선인 가설’이라고 부릅니다. 데이터에 가장 잘 맞는 가설을 구하려면 반복적으로 직선을 수정해야만 합니다.
이처럼 문제를 간단히 만들어 반복적으로 직선을 수정하면 시행착오를 겪으며 성장할 수 있습니다. 이런 기술을 우리는 머신러닝(Machine Learning, 기계학습)이라고 부릅니다. 머신러닝은 인간처럼 생각하는 인공지능은 아니지만, 주어진 문제를 해결하는 능력을 갖춘 인공지능이라고 볼 수 있습니다. 사람처럼 모든 문제에 대해 해결 능력을 갖춘 지능을 강 인공지능이라고 부르고, 특정한 문제에 대해서만 해결 능력을 갖는 인공지능을 약 인공지능이라고 부릅니다.
▼ 딥러닝, 머신러닝, 인공지능의 차이

인공지능 알고리즘 중 시행착오를 겪으며 학습해나가는 알고리즘을 머신러닝이라 부르고, 머신러닝 알고리즘 중, 인공 신경망을 이용한 알고리즘을 딥러닝이라고 부릅니다. 시행착오를 겪지 않는 전문가 시스템은 인공지능의 범주에 들어가지만 머신러닝 알고리즘은 아닙니다.
2. 지도 학습, 비지도 학습, 강화 학습
머신러닝의 학습 방법을 세 가지로 분류할 수 있습니다. 첫 번째로는 데이터에 정답이 있는 지도학습(Supervised Learning), 두 번째는 데이터에 정답이 없는 비지도 학습(Unsupervised Learning), 마지막으로는 인공지능이 직접 체험하며 학습하는 강화 학습(Reinforcement Learning)입니다.
▼ 지도 학습
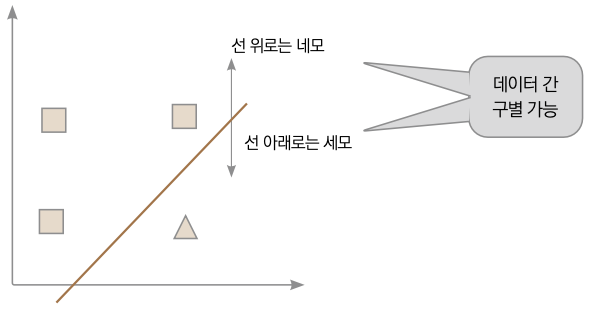
지도 학습은 학습용 데이터에 정답이 붙어 있습니다. 예를 들어 고양이 사진에는 고양이라는 정답이 붙어 있습니다. 토끼 사진에는 토끼라는 정답을 붙여 제공해 학습하고 나서, 학습된 인공지능에 정답 없는 고양이 또는 토끼 사진을 넣어줍니다. 그러면 학습된 인공지능이 고양이와 토끼 사진을 구분한 예측 결과를 출력으로 내놓게 됩니다.
비지도 학습에 사용하는 학습용 데이터에는 정답이 붙어 있지 않습니다. 예를 들면 구매 이력이 담긴 쇼핑 이력이 있다고 합시다. 구매 이력으로 소득 수준을 파악한다든가, 취향을 판단할 수 있습니다. 정답은 없지만 주어진 정보를 이용해 상관관계를 찾아내는 것이 비지도 학습입니다. 비지도 학습은 데이터를 그룹으로 나누는 클러스터링과 이상치 탐지에 사용됩니다.
▼ 비지도 학습
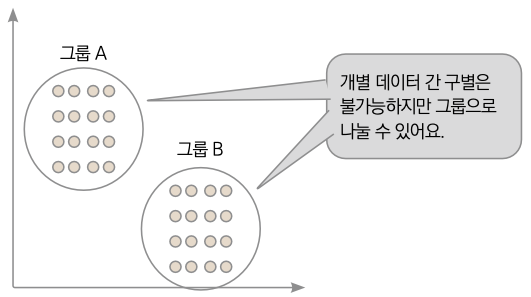
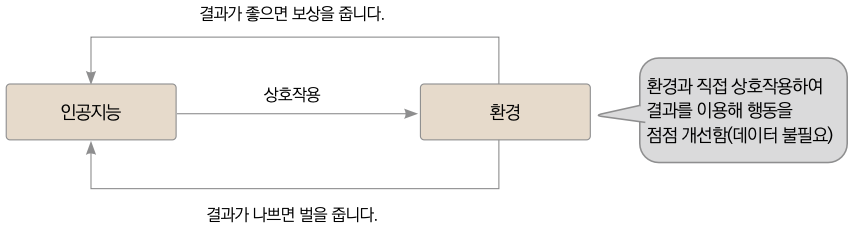
지도 학습과 비지도 학습은 모두 데이터를 입력으로 제공하지만 강화 학습은 데이터를 입력으로 받지 않습니다. 주어진 환경과 인공지능이 직접 상호작용해 인공지능의 행동을 점점 수정해나가도록 학습됩니다. 성공적인 행동에 상을 내리고, 잘못된 행동에 벌을 줘서 인공지능이 직접 자신의 행동을 개선하게 합니다. 구글의 딥마인드가 선보인 알파고는 강화 학습을 이용한 대표적인 예입니다. 이 책에서는 주로 지도 학습을 다루며, 13장 이후에는 비지도 학습의 대표적인 예인 GAN을 알아봅니다.
▼ 강화 학습
3. 왜 딥러닝에 파이토치인가?
딥러닝 모델에는 수많은 알고리즘이 들어 있습니다. 데이터를 처리부터 가중치를 계산하고 수정하는 알고리즘, 가중치를 얼마나 수정해야 되는지 계산하는 알고리즘 등 만들어야 할 알고리즘이 한둘이 아닙니다. 딥러닝 모델을 만들면서 이렇게 많은 알고리즘을 우리가 직접 만들기에는 무리가 있습니다. 다행스럽게도 딥러닝 모델을 만들고 학습하는 데 필요한 도구를 모아놓은 프레임워크가 여럿 있습니다. 대표적인 딥러닝 프레임워크로 텐서플로(TensorFlow), 케라스(Keras), 파이토치(PyTorch)가 있습니다. 우리는 그중에서 파이토치를 사용합니다.
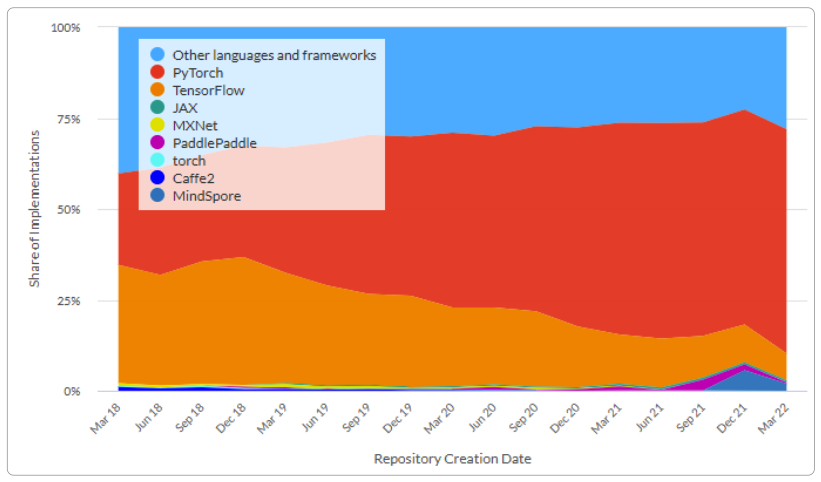
paperswithcode.com에 따르면 2022년 3월 현재 파이토치는 논문에서 가장 많이 사용하는 딥러닝 프레임워크입니다.
▼ paperswithcode.com에서 공개한 2022년 3월 딥러닝 프레임워크 점유율
파이토치는 페이스북, 마이크로소프트 같은 대형 회사부터 대학 연구실까지 많은 사람이 이용합니다. 파이토치 코드는 파이썬 본래의 코드와 유사해 직관적이라는 장점이 있습니다. 텐서플로는 구글에서 공개한 프레임워크로 다양한 플랫폼에서 이용할 수 있습니다. 그렇기 때문에 상황에 따라 어느 프레임워크를 이용할지를 정해야 합니다. 텐서플로는 케라스를 고수준 API로 사용하며 파이썬으로 작성된 오픈 소스 신경망 라이브러리로 파이토치와 마찬가지로 파이썬과 유사한 코딩 스타일을 갖고 있습니다.
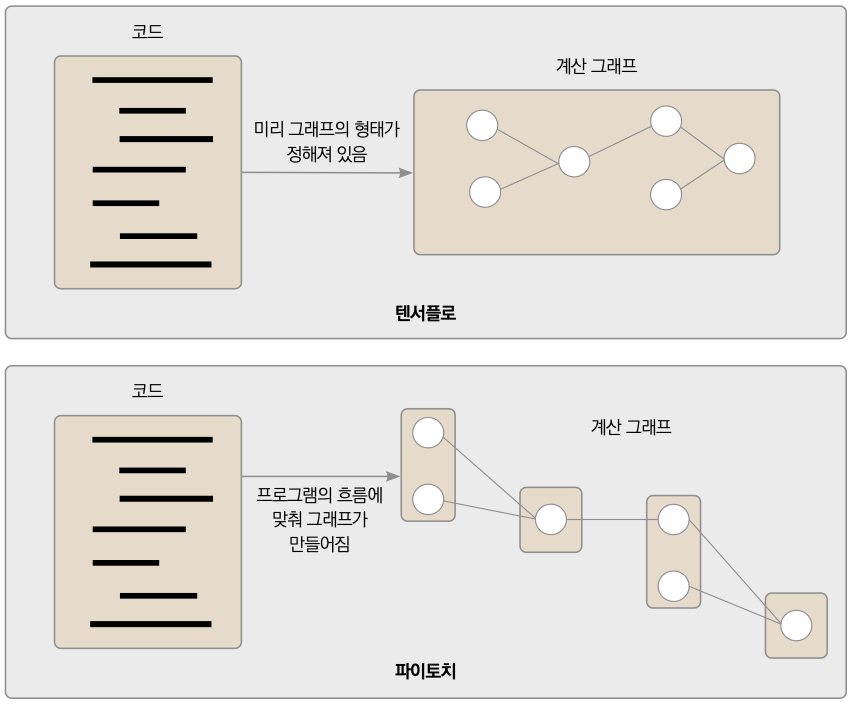
이미지에는 픽셀의 가로 세로 위치와 RGB값이 존재하는데, 파이토치는 RGB값을 가장 먼저 고려합니다. 딥러닝은 계산이 복잡하기 때문에 계산 그래프를 만들어 계산합니다. 파이토치는 동적 계산 그래프를 활용합니다. 정적 계산 그래프는 변수를 정의할 때 그래프 형태가 만들어지고, 동적 그래프는 변수를 호출할 때 그래프를 만들어가며 사용합니다. 파이토치는 동적 계산 그래프를 사용하기 때문에 코드를 읽어오면서 그래프를 만들어가며 사용합니다.
동적 계산 그래프는 중간에 변수의 값을 바꿀 수 있습니다. 반면 정적 계산 그래프는 값을 바꿀 수는 없지만 미리 정의한 순서대로 계산하므로 속도가 빠릅니다.
파이토치, 텐서플로, 케라스가 지원하는 알고리즘과 기능은 거의 같습니다. 서로 코딩 스타일과 문법이 다르고 공개하는 모델이 다릅니다. 그래서 자신이 사용하고자 하는 모델에 따라 프레임워크를 바꿔야 할 때도 있습니다.
▼ 정적 계산 그래프와 동적 계산 그래프의 차이
4. 파이토치 권고 코딩 스타일
파이토치 권고 코딩 스타일을 알아보기 전에 파이토치로 두 텐서의 합을 구하는 아주 간단한 예제를 살펴봅시다. 여기서 텐서는 데이터를 담고 있는 개체를 의미합니다.
▼ 두 텐서의 합
import torch
# 1, 2, 3이 들어 있는 텐서를 만듭니다.
a = torch.tensor([1, 2, 3])
# 4, 5, 6이 들어 있는 텐서를 만듭니다.
b = torch.tensor([4, 5, 6])
# 두 텐서의 합을 구합니다.
c = a + b
# 텐서를 출력합니다.
print(c)
tensor([5, 7, 9])
파이토치는 클래스를 사용하도록 권고합니다. 크게 신경망의 동작을 정의하는 모듈 클래스와 데이터를 다루는 데이터셋 클래스가 있습니다. 즉 파이토치를 이용해 딥러닝 신경망을 학습하려면 ① 모듈 클래스를 이용해 신경망을 만들고, ② 데이터셋 클래스를 이용해 데이터를 불러와 학습하면 됩니다.
파이토치의 딥러닝 신경망은 모두 모듈(nn.Module 클래스)로 구성되어 있습니다. 모듈 클래스의 기본적인 뼈대는 다음과 같습니다.
▼ 파이토치 신경망의 기본 구성
class Net(nn.Module):
def __init__(self):
'''
# 신경망 구성요소 정의
'''
def forward(self, input):
'''
# 신경망의 동작 정의
'''
return output
모듈 클래스는 신경망의 구성요소를 정의하는 init( ) 함수와 신경망의 동작을 정의하는 forward( ) 함수로 구성되어 있습니다. 파이토치는 미리 정의해둔 신경망 모듈을 제공합니다. 파이토치가 제공하는 모듈을 불러와 init( ) 함수 안에 정의합니다. 다음으로 forward( ) 함수에 신경망의 동작을 정의합니다(init( ) 함수에서 정의한 모듈을 연결하거나 필요한 연산 등을 정의합니다).
데이터를 호출하는 데이터셋 클래스의 뼈대는 다음과 같습니다.
class Dataset():
def __init__(self):
'''
필요한 데이터 불러오기
'''
def __len__(self):
'''
데이터의 개수 반환
'''
return len(data)
def __getitem__(self, i):
'''
i번째 입력 데이터와
i번째 정답을 반환
'''
return data[i], label[i]
데이터셋 클래스의 구성요소는 세 가지입니다. 첫 번째로__init__() 함수는 학습에 사용할 데이터를 불러옵니다. 두 번째로 len() 함수는 데이터 개수를 반환합니다. 마지막으로 getitem() 함수는 우리가 지정한 i번째 입력 데이터와 정답을 반환합니다.
모듈 클래스와 데이터셋 클래스를 이용한 딥러닝 학습을 진행하는 뼈대는 다음과 같습니다.
▼ 입력 데이터와 정답 호출
# 데이터로더로부터 데이터와 정답을 받아옴
for data, label in DataLoader():
# 1 모델의 예측값 계산
prediction = model(data)
# 2 손실 함수를 이용해 오차 계산
loss = LossFunction(prediction, label)
# 3 오차 역전파
loss.backward()
# 4 신경망 가중치 수정
optimizer.step()
파이토치는 학습에 사용할 입력 데이터와 정답을 불러오는 데이터로더를 제공합니다. 데이터로 더는 데이터셋 클래스를 입력으로 받아 학습에 필요한 양 만큼의 데이터를 불러오는 역할을 수행합니다. 이 데이터로더로부터 데이터와 정답을 불러와 신경망의 예측값을 계산합니다(여기서 신경망은 앞서 말씀드린 파이토치 모듈입니다). ❶ 예측값을 계산했다면 ❷ 손실 함수를 이용해 신경망의 오차를 계산합니다. ❸ 파이토치의 backward( ) 메서드를 이용해 오차를 역전파한 다음, ❹ step( ) 메서드를 이용해 신경망의 가중치를 수정합니다.

책 내용 중 궁금한 점, 공부하다가 막힌 문제 등 개발 관련 질문이 있으시다면
언제나 열려있는 <스프링 부트 3 백엔드 개발자 되기> 저자님의
카카오채널로 질문해주세요!


