
선형 회귀((Linear Regression))는 머신러닝 기초 알고리즘입니다. 복잡한 알고리즘에 비해서는 예측력이 떨어지지만 데이터 특성이 복잡하지 않을때는 쉽고 빠른 예측이 가능하기 때문에 많이 사용됩니다. 다른 모델과의 성능을 비교하는 베이스라인으로 사용하기도 합니다.
이번에는 선형 회귀 모델로 보험 데이터셋을 학습해 보험료를 예측하고, 선형 회귀의 작동 원리를 이해합니다. 총 4편으로 준비했습니다. 3편은 모델을 활용해 예측하기와 예측 모델 평가하기입니다.
전처리 : 학습셋과 시험셋 나누기
이제 예측하는 실습을 하겠습니다. 원래는 예측 및 평가에서 학습셋과 시험셋을 각각 사용해 오버피팅 문제를 확인하는데, 이번 장에서는 간단하게 시험셋만 가지고 예측/평가를 하겠습니다.
오버피팅(Overfitting)
모델이 학습셋에 지나치게 잘 맞도록 학습되어서 새로운 데이터에 대한 예측력이 떨어지는 현상을 의미합니다. 과적합, 과학습으로도 부릅니다. 5장에서 더 자세하게 다룹니다.

pred = model.predict(X_test)
predict( ) 함수로 예측을 할 수 있으며, 괄호 안에는 예측 대상을 넣어주면 됩니다. 목표 변수가 예측 대상이라고 했죠? 목표 변수를 예측해야 하므로 여기에 들어가는 데이터에는 당연히 목표 변수가 포함되어서는 안 됩니다. 그러면 정답을 알려주는 꼴이 되기 때문입니다. 따라서 학습 때 사용했던 독립변수들을 가진 데이터를 넣어주어야 합니다. train_test_split( ) 함수를 사용하면 X_train과 X_test가 같은 변수를 가지기 때문에 이 부분은 염려할 필요가 없습니다만, 향후 정말 새로운 데이터로 예측할 때는 주의해야 합니다. 독립변수 중 하나라도 빠진 나머지 데이터로 예측을 시도한다면 모델은 예측 과정에서 오류를 발생하게 됩니다.
예측 모델 평가하기
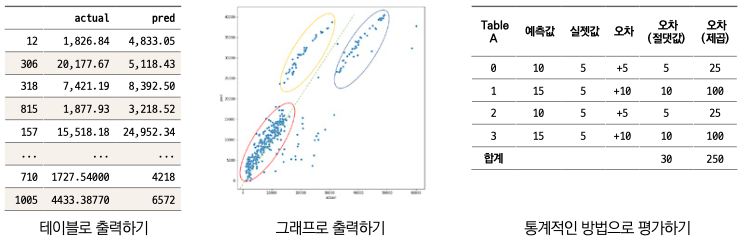
모델을 평가하는 방법으로 ‘테이블로 평가하기, 그래프로 평가하기, 통계(RMSE)적인 방법으로 평가하기’가 있습니다. 각 방법을 알아보겠습니다.
▼ 예측 모델을 평가하는 3가지 방법
테이블로 평가하기
예측한 값은 pred에, 각각 관측치에 대한 실제 정보는 y_test에 저장되어 있습니다. 예측값이 얼마나 정확한지는 pred와 y_test를 비교하는 것으로 단순하게나마 확인할 수 있습니다. pred와 y_test를 각각 별도로 출력해 확인할 수도 있겠지만, 보기 편하게 두 데이터를 합쳐서 테이블 하나로 만들겠습니다.
comparison = pd.DataFrame({'actual': y_test, 'pred': pred})
판다스의 DataFrame( ) 함수로 테이블을 만들었습니다. ‘actual’이라는 컬럼 이름으로 y_test값을 넣고, ‘pred’라는 컬럼 이름으로 pred 데이터값을 넣는 겁니다. 그리고 이 테이블을 comparison에 저장했습니다. 그럼 comparison을 출력하겠습니다.
comparison
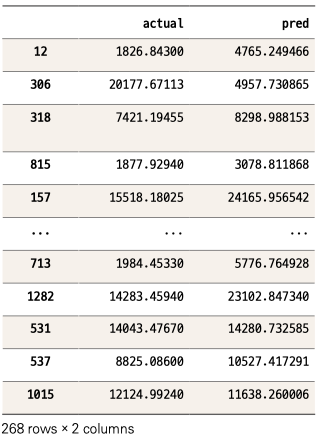
첫 번째 관측치를 보면 실젯값이 1826이고 예측값은 4765 정도로 차이가 큽니다. 마지막 관측치는 실젯값 12124, 예측값 약 11638로 그나마 좀 비슷합니다. 사실 예측 결과를 이런 식으로 하나하나 확인하는 방식에는 한계가 있습니다. 수많은 데이터를 눈으로 다 볼 수는 없으니까요. 산점도(Scatter plot) 그래프를 이용해 한눈에 파악해보겠습니다.
그래프로 평가하기
파이썬에서 그래프를 그리는 데 맷플롯립과 시본 라이브러리를 가장 많이 사용합니다. 두 라이브러리를 임포트합시다.
import matplotlib.pyplot as plt # ❶
import seaborn as sns # ❷
관행으로 ❶ matplotlib은 plt, ❷ seaborn은 sns로 줄여 사용합니다.
그리고 그래프를 만들어볼 텐데, 여기에서는 그래프 크기를 정하는 코드와 산점도 그래프를 만드는 코드 두 줄을 써보겠습니다.
plt.figure(figsize=(10,10)) # ❶ 그래프 크기 정의
sns.scatterplot(x = 'actual', y = 'pred', data = comparison) # ❷
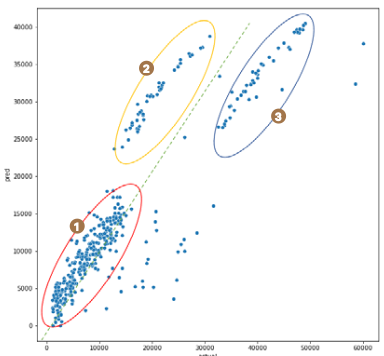
먼저 ❶ ****그래프 크기를 정하고, ❷ ****scatterplot( ) 함수를 이용하여 산점도 그래프를 만들었습니다. 인수로 x축과 y축에 들어갈 데이터 컬럼을 지정합니다. x축에 실젯값인 actual, y축에는 예측값인 pred를 지정했습니다. 그리고 x, y축에 지정해준 컬럼이 속한 데이터를 마지막에 넣어주었습니다.
이해를 돕고자 그래프에 점선과 동그라미를 추가로 그렸습니다. 녹색 점선은 실젯값과 예측값이 정확히 같을 때, 즉 1:1로 매칭되었을 때를 의미합니다. 이 선에 가까울수록 더 잘 예측된 점이라고 해석할 수 있습니다. 이 그래프는 크게 3개의 영역으로 구분해 해석할 수 있습니다. ❶번 빨간 타원의 데이터는 녹색 점선에 가까우므로 실젯값과 예측값이 비슷한, 즉 비교적 예측이 잘된 경우 입니다. 반면 ❷번 노란 타원의 데이터는 전반적으로 실젯값보다 예측값이 더 높게 나타난 경우입니다. 반대로 ❸번 파란 타원은 실젯값보다 예측값이 더 낮은 경우입니다.
그래프로 그렸더니 테이블로 일일이 확인할 때보다 훨씬 평가가 수월합니다. 그런데 그래프로 평가를 하는 방식은 어디까지나 직관적으로 예측력을 확인할 뿐이지, 객관적인 기준이 되지는 않습니다.
통계적인 방법으로 평가하기 : RMSE
이번에는 더 통계적인 방법으로 접근하겠습니다. 연속형 변수를 예측하고 평가할 때 가장 흔하게 쓰이는 RMSE(Root Mean Squared Error, 루트 평균 제곱근 오차, 평균 제곱근 편차)를 사용해보겠습니다. RMSE를 아주 단순하게 말하면 실젯값과 예측값 사이의 오차를 각각 합산하는 개념입니다. 예를들어 2개 데이터가 있고 예측값과 실젯값이 다음과 같다고 가정해봅시다.

각 차이가 -2와 +2로, 이 둘을 더해버리면 0이 됩니다. 차이가 0이라고 하면 완전히 정확하게 예측한 것처럼 보이지만 실제로는 그렇지 않죠? +- 부호 때문에 단순히 차이를 합산하면 이런 문제가 발생합니다. 부호 문제를 없애기 위해 절댓값을 쓰거나 제곱한 값을 사용할 수 있는데, 일반적으로 제곱한 값을 사용합니다. 이를 설명하기 위하여 다음과 같은 두 테이블을 예를 들어 살펴보겠습니다.
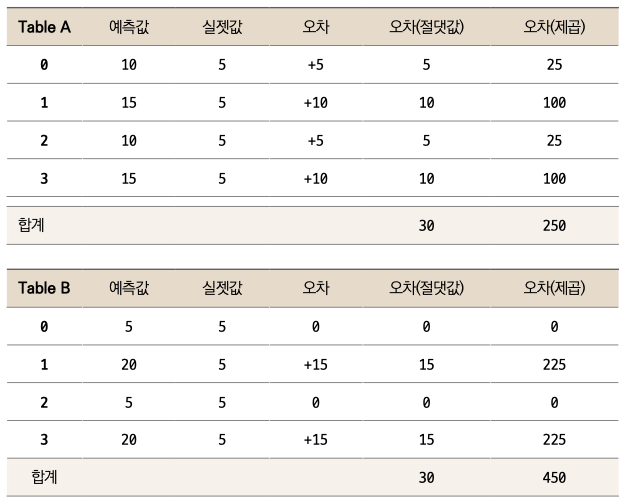
Table A는 오차가 각각 +5, +10, +5, +10으로 비교적 고르게 나왔습니다. 반면 Table B에서는 오차가 0인 게 2건, 나머지 2건이 +15로 꽤 크게 났습니다. 더 오차의 분포가 크다고 할 수 있습니다. 이제 각 테이블의 오차(절댓값)를 보면 두 경우 모두 30으로 같습니다. 즉, 오차에 대한 분포에 상관없이 합산된 값이 같습니다. 반면 오차(제곱)는 Table A에서는 250, B에서는 450으로, Table B에서 훨씬 더 큽니다. 이는 오차가 클수록 (여기서는 1행과 3행) 제곱하면 더 큰 값이 되기 때문입니다. 그래서 통상 오차가 더 큰 때에 더 큰 패널티를 주고자 제곱의 차이를 사용하곤 합니다. 또한 제곱을 사용하는 수식의 장점은 미분이 가능하다는 겁니다. 이 장에서는 왜 오차 계산의 수식에 미분이 필요한지에 대해서 다루지 않지만, 10.6절 ‘이해하기 : 경사하강법’에서 해당 내용을 확인하실 수 있습니다.
이제 더 전문적인 용어를 사용하겠습니다. 절댓값 차이를 이용하는 방법을 MAE(Mean Absolute Error(평균 절대 오차)라고 하며, 제곱 차이를 활용하는 방법은 MSE(Mean Squared Error, 평균 제곱 오차)라고 부릅니다. 앞에 Mean이 붙은 이유는, 차이의 합을 총 개수로 나누어 평균을 내기 때문입니다. Table A를 예로 들어 설명하겠습니다. Table A에서 MAE는 오차(절댓값)의 총합 30을 4로 나눈 7.5가 됩니다. MSE는 오차(제곱)의 합 250을 4로 나누어 62.5가 됩니다.
앞서 MAE보다는 MSE를 더 일반적으로 사용한다고 말씀드렸는데, 여기서 딱 한걸음만 더 나아가 보겠습니다. MSE의 단점은 제곱으로 인해 그 숫자의 규모가 실제 데이터의 스케일에 비해 너무 커진다는 겁니다. 즉, 두 테이블에서의 데이터의 차이는 0, 5, 10, 15 정도 수준인데 MSE는 평균을 낸 값임에도 불구하고 제곱한 값이므로 훨씬 더 큰 62.5라는 숫자를 보여줍니다. 반면 MAE는 7.5로 뭔가 더 합리적으로 보이는 크기의 숫자입니다(실제 데이터에 더 근사한 오차를 보여줍니다). 이 부분을 해소해주기 위해 MSE에 루트를 한 번 씌워줍니다. 그러면 본래 데이터와 스케일도 맞아 떨어집니다. 이렇게 MSE에 루트를 씌워준 값을 RMSE(Root Mean Squared Error, 루트 평균 제곱오차)라고 부르며, 이 지표가 연속형 변수를 예측할 때 가장 일반적으로 쓰이는 평가지표입니다.
▼ 통계적 평가 지표
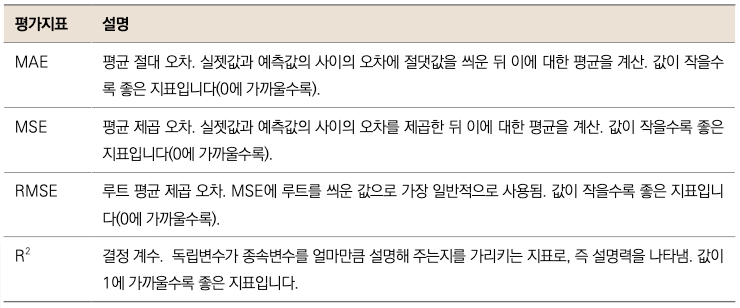
그럼 이제 RMSE를 구해봅시다. 다행히 사이킷런(sklearn) 라이브러리가 MSE, MAE 등 여러 평가지표 함수를 제공합니다. 우선 MSE를 구하는 함수를 쓰고 거기에 루트를 씌워주는 방식으로 RMSE를 계산해보겠습니다.
from sklearn.metrics import mean_squared_error # ❶ MSE 라이브러리 임포트
mean_squared_error(y_test, pred) ** 0.5 # ❷ RMSE 계산 실행
5684.927776334485
❶ MSE 라이브러리를 불러오는 코드입니다. ❷ MSE를 사용하는 코드인데, 괄호 안에 실젯값 데이터, 예측값 데이터를 순서대로 넣어주면 됩니다. ** 0.5는 루트입니다. 파이썬에서는 **가 제곱이므로 0.5를 제곱하면 루트를 씌운 값을 계산합니다.
또 다른 방법으로는 MSE 함수 안에서 squared 매개변수를 False로 설정하면 RMSE를 구할 수 있습니다.
mean_squared_error(y_test, pred, squared = False)
5684.927776334485
약 5684라는 RMSE를 얻을 겁니다. RMSE는 근본적으로 에러에 대한 합을 계산한 것이기 때문에, 작을수록 예측력이 좋다고 할 수 있습니다. 그럼 5684는 작은편에 속할까요, 큰편에 속할까요? 안타깝게도 RMSE를 평가하는 절대적인 기준은 없습니다. 이는 데이터의 특성에 따라 천차만별로 달라질 수 있기 때문에, 어느 수준 이하면 좋은 예측을 보인다는 등의 말을 하기가 어렵습니다. 그래서 RMSE는 절대 평가보다는 상대 평가에 사용합니다. 앞으로 다양한 알고리즘과 활용법을 배울 텐데, 같은 데이터에 여러 가지 모델링을 해보고, 그중 어떤 모델이 가장 뛰어난 예측력을 보이는지를 판단할 때 RMSE가 가장 낮은 모델을 선택하면 됩니다.
마지막으로 R2라는 평가 지표를 알아보겠습니다. R2는 독립변수로 설명되는 종속변수의 분산 비율을 나타내는 통계적 측정값입니다. 무슨 말인지 쉽게 와닿지 않죠? 그림을 보면서 다시 설명해보겠습니다.
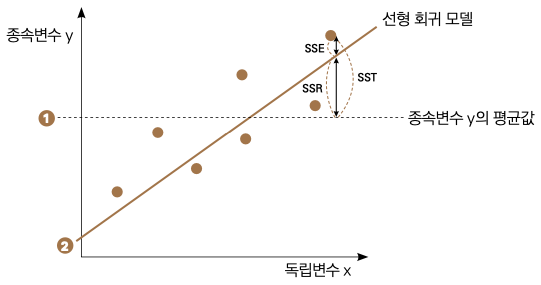
이 그래프에서 ❶ 번 점선은 종속변수의 평균값으로 모델의 성능을 평가하는 비교 대상, 즉 일종의 기준선 역할입니다. ❶ 번 점선으로부터 관측치까지 차이를 SSTSum of Squares Total라고 부릅니다. 그리고 ❷번 실선은 우리가 만든 예측 모델입니다. 특정 데이터의 x값을 기준으로 ❶ 번점선부터 ❷ 번 실선까지의 거리가 SSR(Sum of Squares Regression)입니다. 즉, 평균으로 대충 때려 맞추었을 때와, 우리가 만든 모델을 이용했을 때의 차이죠. 마지막으로 ❷ 번 실선과 실제 데이터까지의 거리는 SSE(Sum of Squares Error)입니다. 우리가 만든 모델이 예측해내지 못한 에러를 나타냅니다. R2는 SST에서 SSR가 차지하는 비율을 나타냅니다.
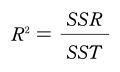
즉, 대충 평균값으로 넣었을 때, 예측값( 평균값)과 실젯값의 차이 중 우리 모델이 얼마만큼의 비율로 실젯값에 가깝게 예측하는지를 의미합니다. 파이썬에서는 아래와 같은 간단한 코드로 R2를 계산할 수 있습니다.
model.score(X_train, y_train)
0.7368220127747351
약 0.74의 값이 나왔습니다. R2는 비율이므로 최대 1까지 나올 수 있으며, 좋은 모델일수록 1에 가깝고 0.7~0.8 이상이면 일반적으로 괜찮은 수치라고 볼 수 있습니다. 우리가 만든 모델은 0.74가 나왔으므로 괜찮은 수준이라고 할 수 있겠네요.
지금까지 크게 세 가지 방법으로 모델을 평가해보았습니다. 사실 가장 먼저 살펴본 테이블을 출력한 결괏값 비교는 데이터를 하나하나 확인해야 해서 거의 사용하지 않습니다만 예측 결과가 실제와 얼마나 다른지 직접 보여드리려는 의도로 소개했습니다. 실제로 사용되는 평가 방법은 RMSE와 R2입니다. 산점도 그래프 같은 그래프를 사용하면 RMSE에 대하여 익숙지 않는 사람에게 설명하기가 편합니다.
4편을 ‘선형 회귀 이해하기‘입니다.

삼성전자에 마케팅 직군으로 입사하여 앱스토어 결제 데이터를 운영 및 관리했습니다. 데이터에 관심이 생겨 미국으로 유학을 떠나 지금은 모바일 서비스 업체 IDT에서 데이터 사이언티스트로 일합니다. 문과 출신이 미국 현지 데이터 사이언티스트가 되기까지 파이썬과 머신러닝을 배우며 많은 시행착오를 겪었습니다. 제가 겪었던 시행착오를 덜어드리고, 머신러닝에 대한 재미를 전달하고자 유튜버로 활동하고 책을 집필합니다.
현) IDT Corporation (미국 모바일 서비스 업체) 데이터 사이언티스트
전) 콜롬비아 대학교, Machine Learning Tutor, 대학원생 대상
전) 콜롬비아 대학교, Big Data Immersion Program Teaching Assistant
전) 콜롬비아 대학교, M.S. in Applied Analytics
전) 삼성전자 무선사업부, 스마트폰 데이터 분석가
전) 삼성전자 무선사업부, 모바일앱 스토어 데이터 관리 및 운영
강의 : 패스트캠퍼스 〈파이썬을 활용한 이커머스 데이터 분석 입문〉
SNS : www.youtube.com/c/데싸노트

