
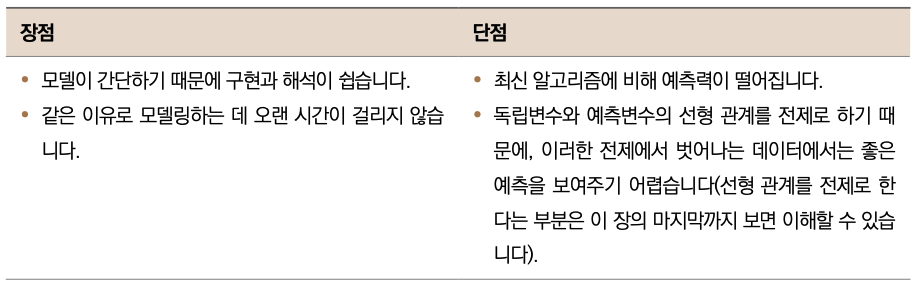
선형 회귀((Linear Regression))는 머신러닝 기초 알고리즘입니다. 복잡한 알고리즘에 비해서는 예측력이 떨어지지만 데이터 특성이 복잡하지 않을때는 쉽고 빠른 예측이 가능하기 때문에 많이 사용됩니다. 다른 모델과의 성능을 비교하는 베이스라인으로 사용하기도 합니다.
이번에는 선형 회귀 모델로 보험 데이터셋을 학습해 보험료를 예측하고, 선형 회귀의 작동 원리를 이해합니다. 총 4편으로 준비했습니다. 1편은 문제 정의와 데이터 불러오기입니다.
선형 회귀 소개
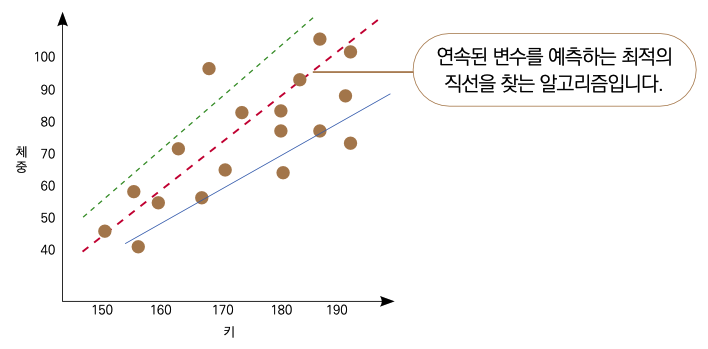
선형 회귀는 가장 기초적인 머신러닝 모델입니다. 여러 가지 데이터를 활용하여 연속형 변수인 목표 변수를 예측해 내는 것이 목적입니다. 예를 들어 몸무게, 나이, BMI, 성별 등을 데이터로 활용하여 키와 같은 연속형 변수를 예측하는 겁니다. 연속형 변수는 165.5cm, 172.3cm, 182.9cm와 같이 연속적으로 이어질 수 있는 변수를 의미합니다. 반면 남성/여성으로 구분되는 성별은 연속형 변수가 아닙니다. 선형 회귀 모델에서는 예측할 종속변수만 연속형 변수면 족합니다. 예측하는 데 사용되는 그외 변수들은 연속형일 필요는 없습니다.
▼ 예시 그래프
▼ 장단점
▼ 유용한 곳
연속된 변수를 예측하는 데 사용됩니다. 예를 들어 BMI(체질량지수), 매출액, 전력 사용량과 같은 변수를 떠올리시면 됩니다.
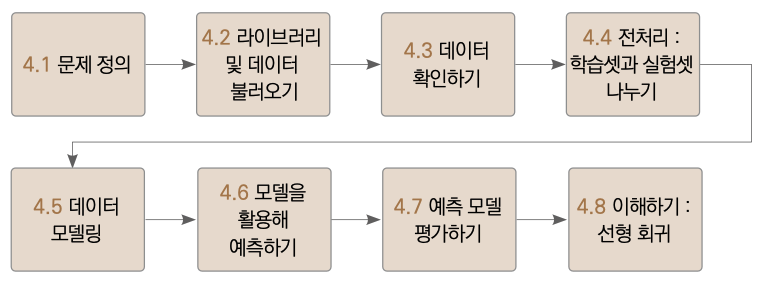
문제 정의 : 한눈에 보는 예측 목표
문제 정의
사람마다 각각 다르게 책정되는 보험료, 과연 어떻게 계산되는 걸까요? 간단하게는 아플 가능성이 더 높아 보이는 사람에게 더 높은 보험료가 책정된다고 생각할 수 있지만, 실제로 이를 계산은 상당히 복잡합니다. 이번에 다룰 데이터셋에는 연령, 성별, BMI, 등의 정보가 담겨 있습니다. 이 데이터를 활용하여 보험료를 예측해보겠습니다.
▼ 예측 목표

라이브러리 및 데이터 불러오기
파이썬에서 데이터를 다룰 때 기본으로 사용되는 라이브러리인 판다스(Pandas)를 불러오겠습니다. 라이브러리를 불러오는 걸 프로그래밍 용어로 ‘임포트( 한다)’라고 합니다.
import pandas as pd # 판다스 라이브러리 임포트
판다스를 불러왔으니 데이터를 불러오는 코드를 작성하겠습니다. 이번에 사용할 데이터는 insurance.csv 파일입니다. URL을 사용하여 불러오겠습니다. pd.read_csv( ) 를 사용하면 판다스 데이터프레임 형태로 데이터를 불러오게 됩니다.
file_url = 'https://media.githubusercontent.com/media/musthave-ML10/data_source/ main/insurance.csv'
data = pd.read_csv(file_url) # 데이터셋 읽기
데이터 확인하기
데이터를 불러왔으니, 불러온 데이터가 어떻게 생겼는지부터 다양한 방법으로 확인하겠습니다. 가장 직관적이고 단순한 방법은 저장한 데이터(data)를 그대로 입력해 출력하는 방식입니다.
data # 전체 데이터 출력
그럼 다음과 같은 결과물을 볼 수 있습니다.
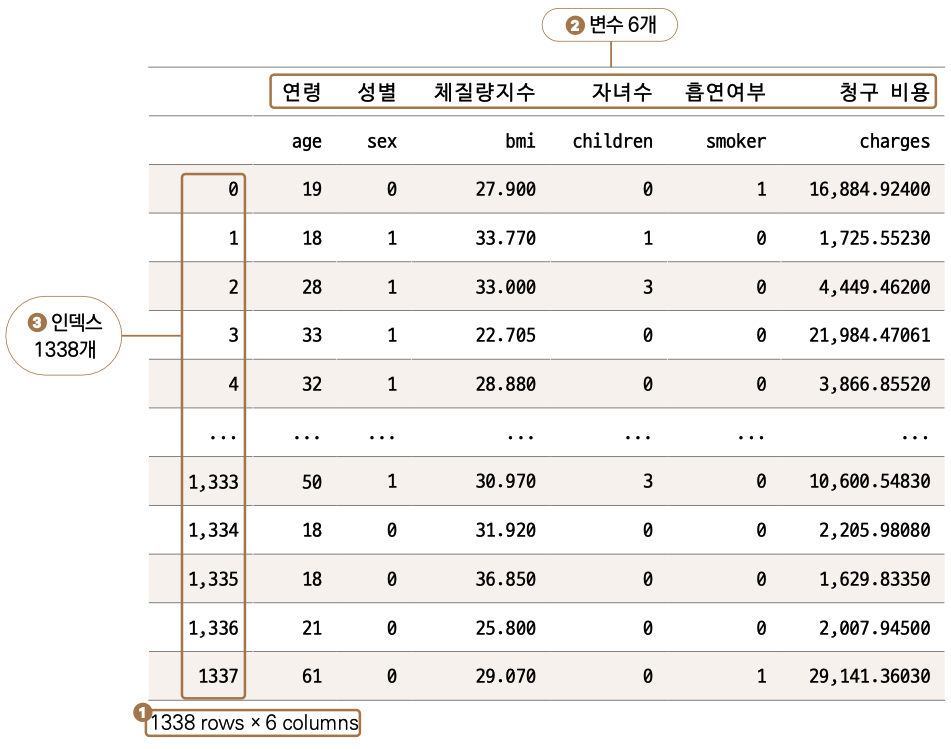
엑셀에서 보는 테이블과 비슷합니다. 테이블 하단 ❶ ****1338 rows X 6 columns에서 볼 수 있듯이 data에는 총 1338줄, 즉 1338명에 대한 데이터가 있습니다. 각 데이터에는 ❷ ****6개의 변수가 있습니다. ❸ ****0부터 1337까지 있는 왼쪽 숫자를 인덱스라고 부르며, 기본값은 줄 번호입니다. 파이썬에서는 대부분 0부터 시작하는 것이 특징입니다. 1338줄 모두를 출력하지 않고 중략되었습니다.
이번에는 판다스에서 제공하는 여러 함수를 사용하여 데이터를 확인하겠습니다. 우선 head( ) 함수로 상위 5줄을 확인해보겠습니다.
data.head() # 상위 5줄 출력
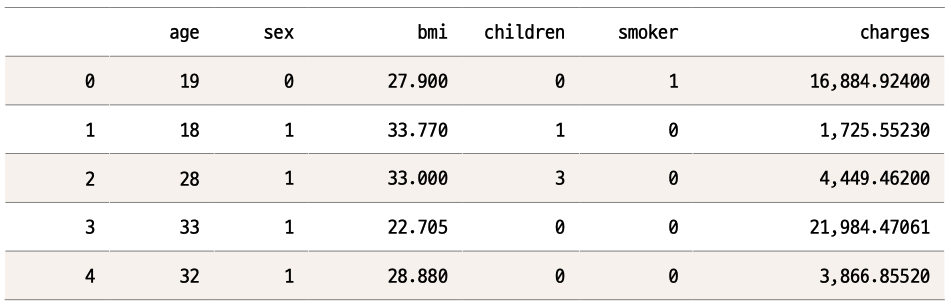
data를 출력했을 때와 같은 형태이지만 5줄만 출력해 더 간결하게 볼 수 있다는 장점이 있습니다. sex와 smoker는 사실 숫자로 표현되는 연속형 변수가 아닌, 범주형 변수입니다. sex는 남성/여성으로 표시되어야 하고, smoker는 흡연자/비흡연자로 표시되어야 하는데, 컴퓨터로 학습하려면 (문자가 아니라) 숫자여야 해서 위와 같이 표기한 겁니다. sex에서는 1이 남자, 0이 여자를 뜻합니다. smoker에서는 1이 흡연자, 0이 비흡연자입니다.
💡 연속형 변수와 범주형 변수
연속형 변수는 나이, 키와 같이 연속적으로 이어지는 변수입니다. 반면 범주형 변수는 이어지는 숫자가 아닌 각 범주로 구성된 변수입니다. 예를 들어 계절이나 성별은 범주형 변수에 속합니다. 연속형 변수에서는 데이터 간의 크고 작음을 비교하거나 사칙연산 등을 할 수 있습니다. 예를 들어 키 180은 170보다 크다고 할 수 있고, 둘 사이의 평균도 구할 수 있습니다. 반면 범주형 데이터에서는 (예를 들어 겨울이 여름보다) 크거나 작다고 할 수 없으며, 평균이라는 개념 또한 존재할 수 없습니다.
이번에는 info( ) 함수로 데이터가 가지고 있는 변수를 확인해봅시다.
data.info() # 컬럼 정보 출력
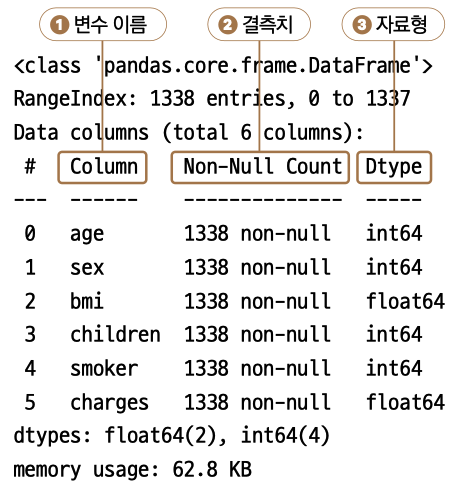
❶ Column에서는 data가 가진 변수 이름을 보여줍니다. 이미 앞에서 확인한 내용이라 특이사항은 없습니다.
❷ Non-NullCount에서는결측치를보여줍니다.Non-Null Count에서 Null은 결측치, 즉 비어 있는 값을 말합니다. non-null은 빈 값이 없다는 뜻입니다. 모든 변수가 1338입니다. 따라서 모든 변수에 빈 값이 없다는 사실을 확인할 수 있습니다.
마지막 ❸ Dtype은 자료형입니다. 모든 변수가 숫자형 데이터이기 때문에 float과 int로만 구성되어 있습니다. 여기에서는 딱히 자료형에 대해서 고려해야 할 사항은 없으니 확인만 하고 넘어가도록 합시다.
마지막으로 describe( ) 를 사용해 통계 정보를 살펴보겠습니다.
data.describe() # 통계 정보 출력
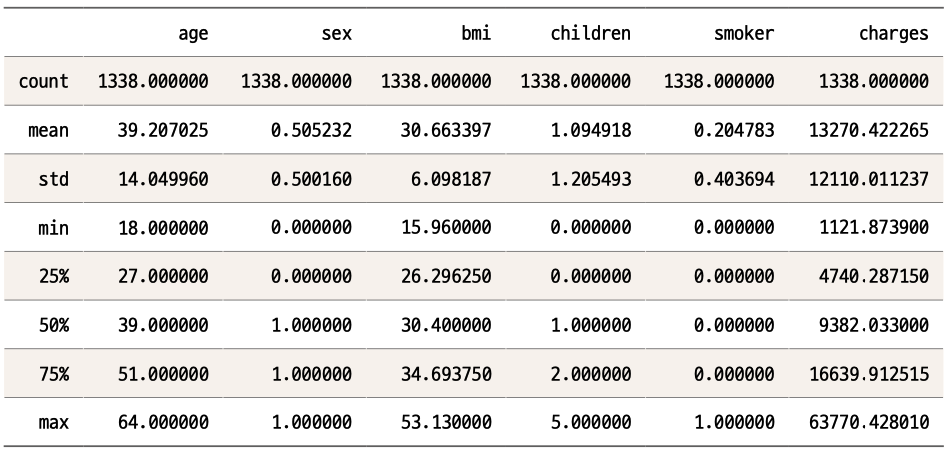
불필요하게 긴 소수점 아래 숫자가 눈에 들어옵니다. 읽기에 편하지 않으니 파이썬에서 기본적으로 제공되는 round( ) 함수를 이용해 반올림해서 읽기 쉬운 형태로 다시 불러오겠습니다. 우리가 반올림할 데이터 테이블은 data.describe( ) 이니, 다음과 같은 코드로 소수점 2자릿수까지 반올림하겠습니다.
round(data.describe(), 2) # 소수점 2째자리까지만 표시해 통계 정보 출력
다음으로 describe( ) 함수의 결과물을 살펴보겠습니다.
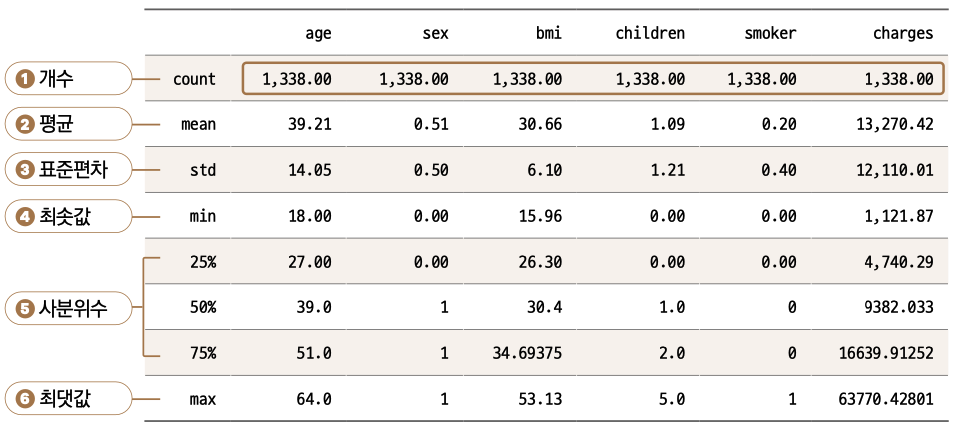
각 변수에 대해 count부터 max까지 다양한 정보를 일목요연하게 확인할 수 있습니다. 우선 ❶ 개수(count)는 모든 변수가 1338로 같은데, 여기에서도 데이터에 결측치가 없음을 확인할 수 있습니다. 그 밑으로는 각각 ❷ 평균(mean), ❸ 표준편차(std), ❹ 최솟값(min), ❺ 사분위수 25%, 50%, 75% 그리고 ❺ 최댓값(max)을 보여줍니다.
💡 사분위수(Quantile)
데이터를 오름차순으로 정리했을 때 25%, 50%, 75% 위치에서 확인한 값입니다. 예를 들어 100개의 값들이 있다고 하면 가장 낮은 숫자부터 하나씩 세어 25번째 데이터, 50번째 데이터, 75번째 데이터가 각각 사분위수 25%, 50%, 75%에 해당합니다. Q1, Q2, Q3라고도 표현합니다.
2편을 ‘전처리 : 학습셋과 시험셋 나누기’입니다.

삼성전자에 마케팅 직군으로 입사하여 앱스토어 결제 데이터를 운영 및 관리했습니다. 데이터에 관심이 생겨 미국으로 유학을 떠나 지금은 모바일 서비스 업체 IDT에서 데이터 사이언티스트로 일합니다. 문과 출신이 미국 현지 데이터 사이언티스트가 되기까지 파이썬과 머신러닝을 배우며 많은 시행착오를 겪었습니다. 제가 겪었던 시행착오를 덜어드리고, 머신러닝에 대한 재미를 전달하고자 유튜버로 활동하고 책을 집필합니다.
현) IDT Corporation (미국 모바일 서비스 업체) 데이터 사이언티스트
전) 콜롬비아 대학교, Machine Learning Tutor, 대학원생 대상
전) 콜롬비아 대학교, Big Data Immersion Program Teaching Assistant
전) 콜롬비아 대학교, M.S. in Applied Analytics
전) 삼성전자 무선사업부, 스마트폰 데이터 분석가
전) 삼성전자 무선사업부, 모바일앱 스토어 데이터 관리 및 운영
강의 : 패스트캠퍼스 〈파이썬을 활용한 이커머스 데이터 분석 입문〉
SNS : www.youtube.com/c/데싸노트

