
부스팅 모델 중 가장 유명한 XGBoos를 활용하여 커플 성사를 예측하고, 그리드 서치(Grid Search)로 하이퍼파라미터를 튜닝하여 더 나은 모델을 만드는 방법을 학습합니다.
총 4편으로 연재됩니다. 4편은 하이퍼파라미터 튜닝 및 XGBoost 이해하기 입니다.
하이퍼파라미터 튜닝 : 그리드 서치
이번 장에서는 그리드 서치를 활용한 하이퍼파라미터 튜닝을 배워보겠습니다. 지금까지 소개한 하이퍼파라미터 튜닝은 임의의 값들을 넣어 더 나은 결과를 찾는 방식이었습니다. 이런 식으로 하나하나 확인하면 모델링 과정을 기다리고 재시도하는 단순 작업을 반복해야 합니다. 그리드 서치를 이용하면 한 번 시도로 수백 가지 하이퍼파라미터값을 시도해볼 수 있습니다.
그리드 서치의 원리는 간단합니다. 그리드 서치에 입력할 하이퍼파라미터 후보들을 입력하면, 각 조합에 대해 모두 모델링해보고 최적의 결과가 나오는 하이퍼파라미터 조합을 알려줍니다. 예를들어 하이퍼파라미터로 max_depth와 learning_rate를 사용한다고 가정합시다. 다음과 같이 하이퍼파라미터별로 다양한 값들을 지정해줍니다.
max_depth = [3, 5, 10]
learaning_rate = [0.01, 0.05, 0.1]
이를 그리드 서치로 적용하면 다음과 같이 9가지 조합이 만들어집니다.
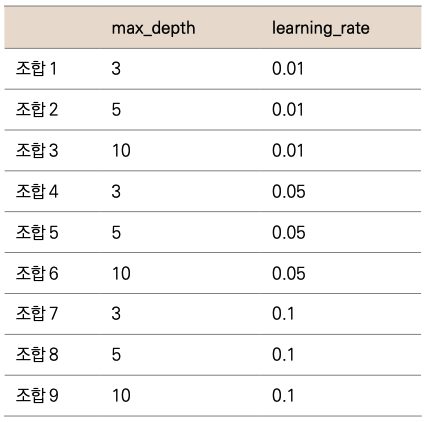
이렇게 9가지 조합을 각각 모델링하게 되는데, 보통 그리드 서치에서는 6장에서 배운 교차검증도 함께 사용하기 때문에 교차검증의 횟수만큼 곱해진 횟수가 모델링됩니다. 예를 들어 위의 9가지 조합에 K-폴드값을 5로 교차검증을 한다면 9 _ 5 = 45회의 모델링을 진행합니다. 모델링 결과 가 좋은 매개변수 조합을 알려주고, 해당 하이퍼파라미터셋으로 예측까지 지원합니다.
더 많은 하이퍼파라미터 종류와 더 많은 후보를 넣으면 더 좋은 결과를 얻을 수 있는 가능성도 높아지지만, 그만큼 학습 시간이 길어질 수 있습니다. 따라서 소요 시간을 고려하여 적정 수준으로 설정해주는 게 좋습니다.
그리드 서치 모듈은 사이킷런 라이브러리의 model_selection에서 불러올 수 있습니다.
from sklearn.model_selection import GridSearchCV # 임포트
그리드 서치에 넣어줄 매개변수 4개를 딕셔너리 형태로 입력하면 됩니다.
parameters = {
'learning_rate': [0.01, 0.1, 0.3],
'max_depth': [5, 7, 10],
'subsample': [0.5, 0.7, 1],
'n_estimators': [300, 500, 1000]
} # 하이퍼파라미터 셋 정의
각 매개변수의 의미는 다음과 같습니다.
- learning_rate : 경사하강법에서 ‘매개변수’를 얼만큼씩 이동해가면서 최소 오차를 찾을지, 그 보폭의 크기를 결정하는 하이퍼파라미터입니다. 기본적으로 보폭은 미분계수에 의해 결정되지만, learning_rate를 크게 하면 더 큰 보폭을, 작게 하면 그만큼 작은 보폭으로 움직입니다. learning rate를 우리말로 학습률이라고 합니다. 학습률 크기에 따라 최적의 에러를 찾는 과정은 다음과 그림과 같습니다.
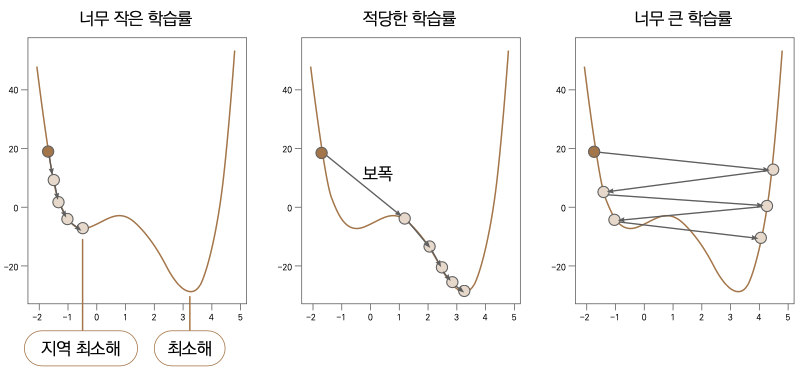
Note 학습률과 보폭
학습률은 입력, 보폭은 그 결과입니다. 큰 학습률을 사용하면 결과적으로 보폭도 커집니다.
왼쪽 그래프는 너무 작은 학습률을 쓴 경우입니다. 보폭이 너무 조금씩 움직이다 보니 최소 에러값을 찾는 데 상당한 시간이 들고 지역 최소해에 빠질 가능성도 상대적으로 커집니다. 반대로 오른쪽 그래프는 너무 큰 학습률을 사용해서 너무 성큼 움직이기 때문에 최소 에러를 정확히 찾지 못하고 좌우로 계속 넘어다닙니다. 가운데의 그래프가 가장 이상적입니다. 이처럼 적절한 크기의 학습률을사용해야큰시간을들이지않고최소오차지점을찾아낼수있습니다.
- max_depth : 각 트리의 깊이를 제한합니다.
- subsample : 모델을 학습시킬 때 일부 데이터만 사용하여 각 트리를 만듭니다. 0.5를 쓰면 데이터의 절반씩만 랜덤 추출하여 트리를 만듭니다. 이 또한 오버피팅을 방지하는 데 도움이 됩니다.
- n_estimators : 전체 나무의 개수를 정합니다.
위와 같이 매개변수를 딕셔너리 형태로 설정해준 뒤에는, 알고리즘 속성이 부여된 빈 모델을 만듭니다.
model = xgb.XGBClassifier() # 모델 객체 생성
이제 그리드 서치를 수행할 준비를 모두 갖춰졌으니, 모델을 생성할 GridSearchCV() 함수를 다음과 같이 설정해줍니다. 모델(model)과 딕셔너리형의 하이퍼파라미터셋(parameters)은 필 수, 그외는 선택 사항입니다.
gs_model = GridSearchCV(model, parameters, n_jobs=-1, scoring='f1', cv = 5)
# 그리드서치 객체 생성
n_jobs는 사용할 코어 수이고, scoring은 모델링할 때 어떤 기준으로 최적의 모델을 평가할지를 정의합니다. 여기서는 F1-점수를 기준으로 판단하도록 설정했습니다. 그리고 cv는 교차검증에 사용할 K-폴드값입니다. 여기서는 5로 설정했습니다. 이제 gs_model을 가지고 학습을 시키겠습니다. 학습시키는 코드는 기존의 모델링과 같습니다.
gs_model.fit(X_train, y_train) # 학습
이번에는 학습 완료까지 상당한 시간이 소요될 겁니다. 하이퍼파라미터셋이 총 4종류에 3개씩 값이 있으니 34으로 총 81번의 모델링을 진행하고 나서 교차검증 5회를 실행하므로 총 405번의 모델링 작업이 이뤄집니다.
그리드 서치는 학습이 완료된 후, 가장 좋은 성능을 보인 하이퍼파라미터 조합 정보를 보관합니다. 아래 코드로 최적의 조합을 확인할 수 있습니다.
gs_model.best_params_ # 최적의 하이퍼파라미터 출력
{'learning_rate': 0.3, 'max_depth': 5, 'n_estimators': 1000, 'subsample': 0.5}
또한 이전의 모델링 과정과 동일하게, 그리드 서치를 이용해서 새로운 데이터를 예측할 수도 있습니다. 이때 적용되는 모델은 최적의 하이퍼파라미터 조합이 자동으로 반영됩니다.
pred = gs_model.predict(X_test) # 예측
그럼 예측된 값에 대한 정확도(accuracy_score)와 분류 리포트(classification_report)를 확인하겠습니다.
accuracy_score(y_test, pred) # 정확도 계산
0.8634686346863468
print(classification_report(y_test, pred)) # classification report 출력
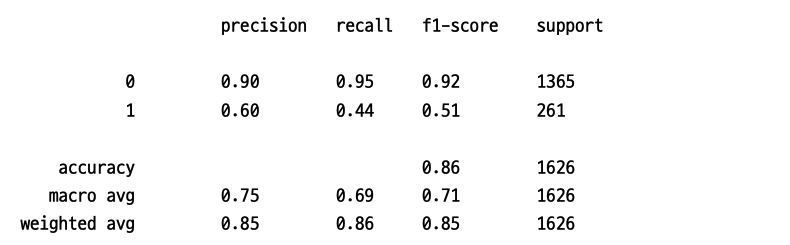
정확도는 아주 미세하게 올라갔고, F1-점수는 0.02 상승했습니다. 일반적으로 하이퍼파라미터 튜닝으로 엄청난 개선을 얻기는 쉽지 않습니다. 예측에는 피처 엔지니어링과 모델 알고리즘 선정이 큰 영향을 미칩니다. 하이퍼파라미터 튜닝은 조금이라도 더 나은 모델을 만드는 역할입니다.
중요 변수 확인
선형 회귀와 로지스틱 회귀에서는 계수로, 결정 트리에서는 노드의 순서로 변수의 영향력을 확인했습니다. 부스팅 모델은 이전 모델들보다 훨씬 복잡한 알고리즘이기 때문에 단순하게 변수의 영향력을 파악하기는 어렵지만, XGBoost에 내장된 함수는 변수의 중요도까지 계산해줍니다. 단, 그리드 서치로 학습된 모델에서는 이 기능을 사용할 수 없으니 그리드 서치에서 찾은 최적의 하이퍼파라미터 조합으로 다시 한번 학습을 시키겠습니다.
model = xgb.XGBClassifier(learning_rate = 0.3, max_depth = 5,
n_estimators = 1000, subsample = 0.5, random_state=100) # 모델 객체 생성
model.fit(X_train, y_train) # 학습
학습이 완료되었으면 feature_importances_에서 변수 중요도(피처 중요도feature importance라고도 합니다)를 확인할 수 있습니다.
model.feature_importances_ # 변수 중요도 확인

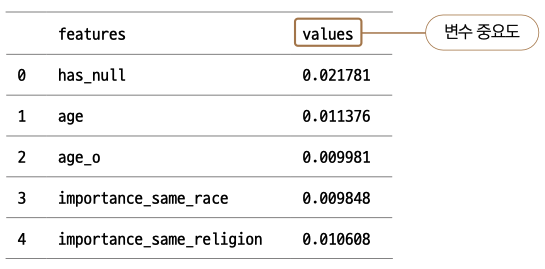
결괏값은 넘파이 형태이기 때문에 변수 이름 없이 순서대로 숫자만 나열됩니다. X_train의 변수 이름을 사용하여 feature_imp라는 이름의 데이터프레임으로 만들어 변수 이름과 매칭시키겠습니다.
feature_imp = pd.DataFrame({'features': X_train.columns, 'values': model. feature_importances_}) # 데이터프레임으로 변환
feature_imp에 head( ) 를 호출해 제대로 만들어졌는지 확인해봅시다.
feature_imp.head() # 상위 5줄 출력
변수 중요도를 내림차순으로 정리하여 확인해봅시다. barplot( ) 으로 바 그래프를 그려 상위 10개의 중요 변수를 확인하겠습니다.
plt.figure(figsize=(20, 10)) # 그래프 크기 설정
sns.barplot(x='values', y='features', # ❶
data=feature_imp.sort_values(by='values', ascending=False).head(10)) # ❷
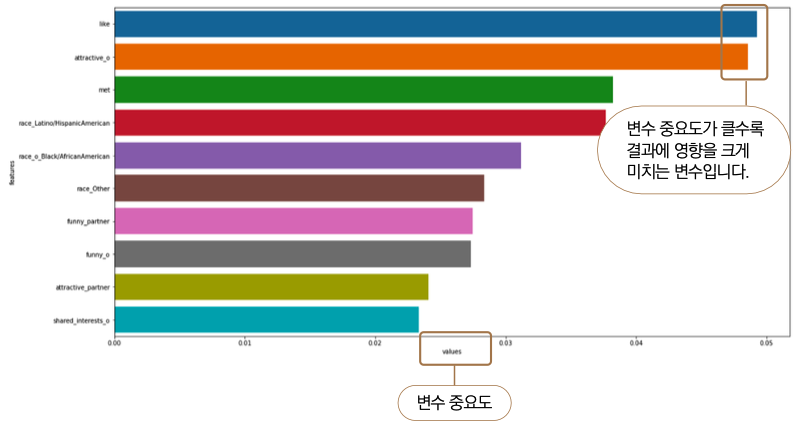
❶x축에는 values( 중요도), y축에는 features 컬럼을 설정했습니다. ❷ ****sort_values( ) 를 사용해 컬럼 ‘values’를 기준으로 내림차순 정렬합니다. 그 뒤에 head( ) 를 이어 붙여서 상위 10개 항목만 불러 그래프를 출력합니다.
선형 회귀와 로지스틱 회귀에서는 계수 부호와 크기를 보고 직관적으로 이해할 수 있습니다. 결정트리에서 각 노드는 어떤 변수에서 어떤 값 기준으로 다음 노드를 나누는지 보여주기 때문에 역시 직관적으로 이해할 수 있습니다. 반면 여기서 나타나는 values는 상대적인 중요도를 계산한 값이기 때문에 직관적으로 이해하기가 어렵습니다. 또한 중요하다고 나타난 변수들이 긍정적인 영향인지 부정적인 영향인지까지는 보여주지 않으므로 해석에 유의할 필요가 있습니다.
이해하기 : XGBoost
XGBoost를 얘기하기에 앞서 트리 모델의 진화 과정을 간략하게 알아보겠습니다.
▼ 트리 모델의 진화 과정
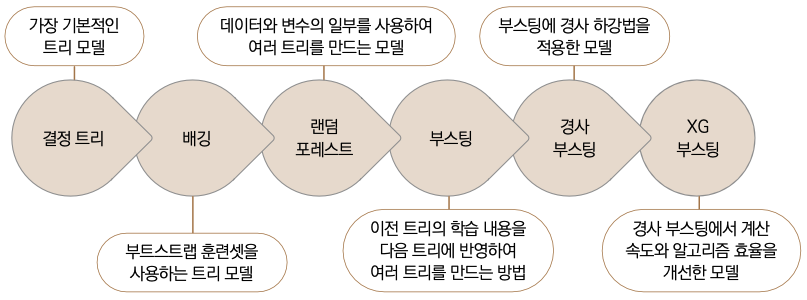
결정 트리와 랜덤 포레스트는 지난 장에서 다뤘습니다. 배깅(Bagging), 부스팅(Boosting), 경사 부스팅(Gradient Boosting)은 이 책에서 선정한 톱 10 알고리즘에 포함되지 않았으니 간략하게 소개하겠습니다.
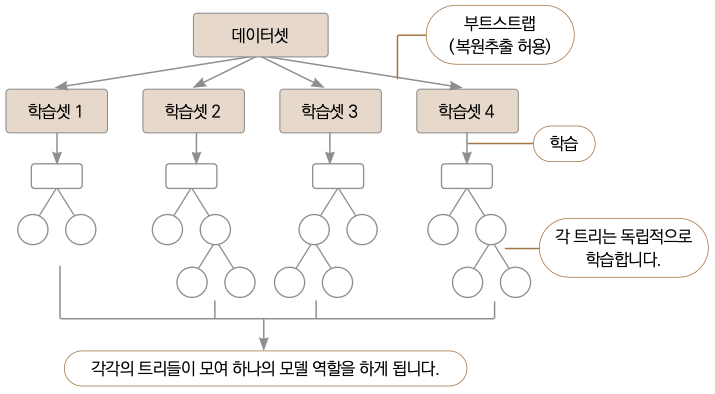
배깅
배깅은 부트스트랩(Bootstrap) 훈련셋을 사용하는 트리 모델입니다. 부트스트랩은 데이터의 일부분을 무작위로 반복 추출하는 방법입니다. 이러한 식으로 추출한 데이터의 여러 부분집합을 사용해 여러 트리를 만들어 오버피팅을 방지합니다. 이 방법은 랜덤 포레스트에도 포함된 내용입니다. 랜덤 포레스트는 배깅에서 한 단계 더 발전된 모델입니다.
▼ 배깅 학습 방법
에이다부스트
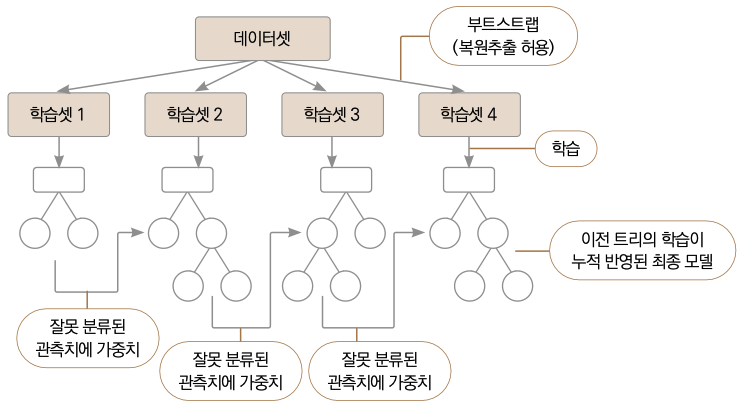
부스팅(Boosting)은 랜덤 포레스트에서 한 단계 더 발전한 방법으로 역시 여러 트리를 만드는 모델입니다. 가장 큰 차이점은 랜덤 포레스트에서 각 트리는 독립적이나, 부스팅에서는 그렇지 않다는 겁니다. 다시 말해 랜덤 포레스트에서는 각 트리를 만들 때 이전에 만든 트리와 상관없이 새로운 데이터 부분집합과 변수 부분집합을 이용합니다. 반면 부스팅은 각 트리를 순차적으로 만들면서 이전 트리의 정보를 이용합니다. 부분집합을 이용해 첫 트리를 만들고 난 후, 해당 트리의 예측 결과를 반영하여 두 번째 트리를 만들어서 첫 번째 트리와의 시너지 효과를 키웁니다. 트리를 계속하여 만들 때마다 이런 식으로 이전 트리의 정보를 이용한다는 점이 랜덤 포레스트와 다릅니다.
부스팅의 대표 알고리즘인 에이다부스트(AdaBoost, Adaptive Boosting)는 단계적으로 트리를 만들 때 이전 단계에서의 분류 결과에 따라 각 데이터에 가중치를 부여/수정합니다. 예를 들어 이전 트리에서 가중치가 덜 부여되고 잘못 분류된 데이터들에 더 높은 가중치를 부여하고, 후속 트리에서는 가중치가 높은 데이터를 분류하는 데 우선순위를 둡니다. 이러한 방식으로 트리 여러 개를 만들면 분류가 복잡한 데이터셋도 세부적으로 나눌 수 있는 모델이 만들어집니다.
▼ 에이다부스트 학습 방법
경사 부스팅과 XGBoost
에이다부스트는 각 데이터에 가중치를 부여/수정하는 방식으로 트리를 만듭니다. 반면 경사 부스팅(Gradient Boosting)은 경사하강법을 이용하여, 이전 모델의 에러를 기반으로 다음 트리를 만들어갑니다. 경사 부스팅으로 구현한 알고리즘으로 XGBoost, LightGBM, Catboost 등이 있습니다.
▼ 경사 부스팅 학습 방법
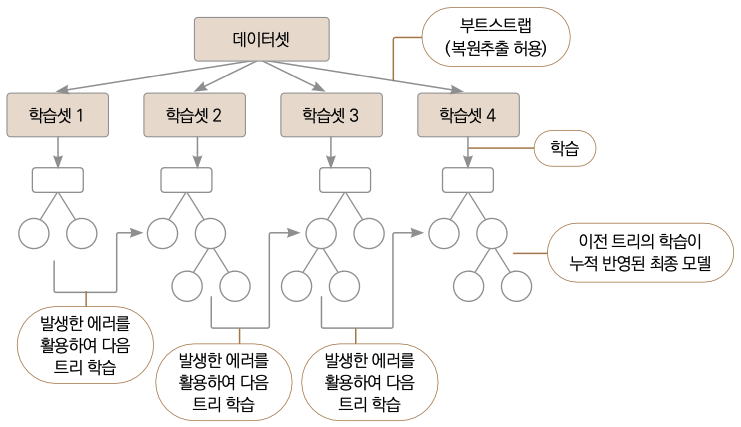
XGBoost는 Extreme Gradient Boosting을 줄인 것으로, XGBoost가 기존의 경사 부스팅보다 특별한 이유는 계산 성능 최적화와 알고리즘 개선을 함께 이루었기 때문입니다. 우선 계산 성능 최적화에 있어서, XGBoost 이전의 부스팅 모델은 트리를 순차적으로 만들어내기 때문에 모델링 속도가 느립니다. XGBoost도 마찬가지로 순차적으로 트리를 만들지만, 병렬화(Parallelization), 분산 컴퓨팅(Distributed Computing), 캐시 최적화(Cache Optimization / Cache-Aware Access) 등을 활용해 계산 속도가 훨씬 빠릅니다.
또한 알고리즘도 개선해 경사하강법보다 더 발전된 형태로 최솟값을 찾아냅니다. 기존 경사하강법이 접점의 기울기를 계산하고 매개변수를 이동한 반면, XGBoost에서는 2차 도함수(2번 미분한 함수)를 활용해 더 적절한 이동 방향과 이동 크기를 찾아내어 더 빠른 시간에 전역 최솟값에 도달합니다.
또 한 가지 중요한 개선 사항은 정규화 하이퍼파라미터(Regularization Hyperparameter) 지원입니다. 트리 모델이 진화할수록 더 좋은 예측 성능을 보이는 동시에 반대급부로 오버피팅 문제가 더 심각해질 수 있습니다. XGBoost는 이러한 부작용을 줄일 목적으로 LASSO(L1)와 Ridge(L2) 정규화 하이퍼파라미터를 지원합니다(더 구체적인 설명은 11.6절 ‘하이퍼파라미터 튜닝’ 참조). 그 밖에도 애매하게 예측된 관측치에 높은 가중치를 부여하는 가중치 분위수 스케치(Weighted Quantile Sketch), 결측치를 유연하게 처리해내는 희소성 인식(Sparsity Aware) 등을 포함하여 성능을 개선시켰습니다.
그리드 서치에 다른 하이퍼파라미터값들을 넣어 더 나은 예측을 보이는 조합을 찾을 수 있는지 시도해보세요.
가중치 분위수 스케치
최적의 분할을 찾기 위해 각 변수에 대한 히스토그램을 만듭니다. 히스토그램의 기 둥의 경계는 최상의 분할지점을 찾기 위 한 후보로 사용되는데, 가중 분위수 스케 치에서는 각 기둥이 동일한 가중치를 갖 도록 만들어집니다.
학습 마무리
스피드데이팅 데이터셋을 이용해서 커플 성사 여부를 예측하는 모델을 만들어보았습니다. 이 과정을 되짚어보겠습니다.

삼성전자에 마케팅 직군으로 입사하여 앱스토어 결제 데이터를 운영 및 관리했습니다. 데이터에 관심이 생겨 미국으로 유학을 떠나 지금은 모바일 서비스 업체 IDT에서 데이터 사이언티스트로 일합니다. 문과 출신이 미국 현지 데이터 사이언티스트가 되기까지 파이썬과 머신러닝을 배우며 많은 시행착오를 겪었습니다. 제가 겪었던 시행착오를 덜어드리고, 머신러닝에 대한 재미를 전달하고자 유튜버로 활동하고 책을 집필합니다.
현) IDT Corporation (미국 모바일 서비스 업체) 데이터 사이언티스트
전) 콜롬비아 대학교, Machine Learning Tutor, 대학원생 대상
전) 콜롬비아 대학교, Big Data Immersion Program Teaching Assistant
전) 콜롬비아 대학교, M.S. in Applied Analytics
전) 삼성전자 무선사업부, 스마트폰 데이터 분석가
전) 삼성전자 무선사업부, 모바일앱 스토어 데이터 관리 및 운영
강의 : 패스트캠퍼스 〈파이썬을 활용한 이커머스 데이터 분석 입문〉
SNS : www.youtube.com/c/데싸노트

