
트리 모델 계열의 근간인 결정 트리를 학습시켜 연봉을 예측합니다. 모델링에서 발생하는 중요한 이슈인 오버피팅 개념과 해결 방법을 알아봅니다. 2편은 범주형 데이터, 전처리 : 결측치 처리 및 더미 변수 변환입니다.
1. 전처리 : 범주형 데이터
가장 먼저 처리할 변수는 종속변수인 class입니다. 차후 해석에 혼선이 없도록 50K 이하를 0, 초과를 1로 변경하겠습니다.
data['class'] = data['class'].map({'<=50K': 0, '>50K': 1}) # 숫자로 변환
💡사실 이 데이터의 원본에는 ‘<=50K’의 맨 앞부분에 공란이 하나 포함되어 있습니다. 그래서 위의 코드가 제대로 작동하지 않을 수 있는데, 앞서 데이터를 불러오는 과정에서 맨 앞자리의 공란을 모두 제거해주었기 때문에 아무런 이슈 없이 처리할 수 있습니다.
1.1 object형의 변수 정보 확인하기
다음은 독립변수의 범주형 데이터를 다루겠습니다. 이 데이터에 변수는 13개뿐입니다. 그래서 어떤 변수가 object형인지 쉽게 눈으로 확인할 수 있으나, 변수가 100개 이상이 된다면 다른 접근 방법이 필요합니다. 범주형 데이터가 얼마나 있는지 확인하는 방법을 알아보겠습니다.
data['age'].dtype
dtype('int64')
age 변수는 int64형의 데이터입니다(object형은 object로 출력됩니다). for문를 활용하여 모든 변수의 자료형을 확인하겠습니다.
for i in data.columns: # ❶ 순회
print(i, data[i].dtype) # ❷ 컬럼명과 데이터 타입 출력
age int64 workclass object education object education-num int64 marital-status object occupation object relationship object race object sex object capital-gain int64 capital-loss int64 hours-per-week int64 native-country object class int64
❶ data.columns로 컬럼명을 지정하고 ❷ 해당 변수의 자료형을 dtype으로 확인했습니다. 출력 결과는 아직까지 info( ) 함수와 크게 다르지 않습니다.
obj_list = [] # 빈 리스트
for i in data.columns:
if data[i].dtype == 'object': # ❶ 데이터타입이 object이면
obj_list.append(i) # ❷ 리스트에 변수 이름을 추가
❶ dtype이 object인지 아닌지를 확인합니다. object가 맞으면 ❷ 리스트( obj_list)에 추가합니다. 그럼 obj_list를 확인하겠습니다.
obj_list # 모아진 변수 확인
['workclass', 'education', 'marital-status', 'occupation', 'relationship', 'race', 'sex', 'native-country']
1.2 전처리할 변수 선별하기
이번에는 각 변수의 고윳값 개수를 nunique( ) 함수를 이용하여 확인하겠습니다.
for i in obj_list:
print(i, data[i].nunique()) # ❶ 변수 이름과 고윳값 개수 확인
workclass 8 education 16 marital-status 7 occupation 14 relationship 6 race 5 sex 2 native-country 41
❶ 변수의 이름과 값의 개수를 같이 볼 수 있도록 print() 안에 둘 다 넣어 출력했습니다. describe( ) 로 본 정보와 같습니다. 변수 개수가 상당히 많을 때는 describe( ) 함수 대신 이와 같은 방법을 사용하면 간결하게 확인할 수 있답니다.
범주형 변수를 다룰 때는 더미 변수로 바꾸어 활용하는 방법을 기본으로 생각하는 게 좋습니다. 이전 장에서 배웠다시피, 더미 변수를 사용하면 값의 종류만큼 새로운 변수들이 생겨나기 때문에, 값의 종류가 수백 개면 그만큼 많은 변수가 생겨납니다. 필요하다면 수백 개의 변수를 감수하고서 모델링을 해야 하지만 꼭 필요하지 않다면 변수 수를 줄일 방법을 강구할 필요가 있습니다.
값의 종류가 10개 미만인 변수는 그대로 두고, 10개 이상인 변수만 확인하여 조치할지를 검토하겠습니다.
위의 코드에 if절을 추가해 unique가 10개 이상인 변수들만 다시 추려보겠습니다.
for i in obj_list: # 순회
if data[i].nunique() >= 10: # 변수의 고윳값이 10보다 크거나 같으면
print(i, data[i].nunique()) # 컬럼명과 고윳값 개수 출력
세 가지 변수(education, occupation, native-country)가 출력되었군요. 각각을 살펴보고 각기 다른 방법으로 처리하는 연습을 하겠습니다.
1.3 education 변수 처리
우선 education 변수의 정보를 value_counts( ) 로 살펴봅시다.
data['education'].value_counts() # 고윳값 출현 빈도 확인
HS-grad 15784 Some-college 10878 Bachelors 8025 Masters 2657 Assoc-voc 2061 11th 1812 Assoc-acdm 1601 10th 1389 7th-8th 955 Prof-school 834 9th 756 12th 657 Doctorate 594 5th-6th 509 1st-4th 247 Preschool 83 Name: education, dtype: int64
미국의 교육 시스템에 대한 정보라 완전하게 이해하기는 어려울 겁니다. 초중고에 속하는 1~12학년까지의 값과, Bachelors나 Masters 같은 학위 이름들이 있습니다. 이 경우는 범주형 변수지만 서열화가 가능하기 때문에 비교적 다루기 쉬운 편입니다. 예를 들어 초등학교를 가장 낮은 숫자로, 박사학위를 가장 높은 숫자로 나타낼 수 있습니다.
기본적으로 범주형 변수를 숫자로 대체시킬 때는 주의를 해야 합니다. 5.4절 ‘전처리 : 범주형 변수 변환하기(더미 변수와 원-핫 인코딩)’에서 더미 변수를 설명할 때 말씀드렸죠? 하지만 지금과 같은 경우는 각 값들의 서열이 명백하기 때문에, 숫자로 바꿔주어도 전혀 문제가 없습니다. 앞에서 class를 0과 1로 바꾸어주었을 때처럼 map( ) 함수를 활용하여 숫자로 변경하면 되는데, 공교롭게도 해당 데이터에는 이에 대한 변수가 이미 준비되어 있습니다. 잠시 head( ) 함수로 확인한 결과물을 다시 보겠습니다.
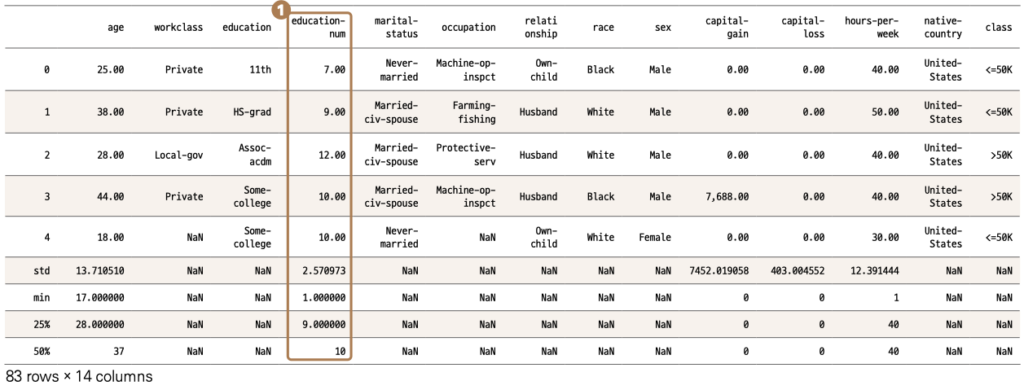
❶ education-num 변수를 보니 education 정보를 숫자로 표현한 것 같습니다. 기대하는 바처럼 서열순인지 확인은 해봐야겠죠?
education-num에 어떤 숫자들이 들어 있는지 unique( ) 함수를 써서 알아봅니다. 변수가 제대로 서열화되었는지를 넘파이의 sort( ) 를 사용하여 오름차순으로 정리해 확인하겠습니다.
np.sort(data['education-num'].unique())
array([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16]),
dtype=int64)
1에서부터 16까지의 숫자가 있습니다. 각 숫자가 어떤 education값과 매칭되는지를 확인할 차례입니다. 기대하는 바는 일대일 매핑인데, 실제로 그렇지 않을 가능성도 염두에 두고 확인을 해야 합니다.
1에 대한 매핑을 확인합시다. education-num이 1인 데이터만 모아서 그중 education 변수에 어떤 값들이 있는지를 확인하면 됩니다. 한 번에 한 줄씩 코드를 늘려가며 최대한 쉽게 설명하겠습니다.
우선 education-num이 1인지 확인합니다.
data['education-num'] == 1
0 False
1 False
2 False
3 False
4 False
...
48837 False
48838 False
48839 False
48840 False
48841 False
Name: education-num, Length: 48842, dtype: bool
1이면 True, 아니면 False입니다. 이 정보를 가지고 인덱싱을 하여, True인 경우만 불러오겠습니다(즉 1인 경우).
data[data['education-num'] == 1]
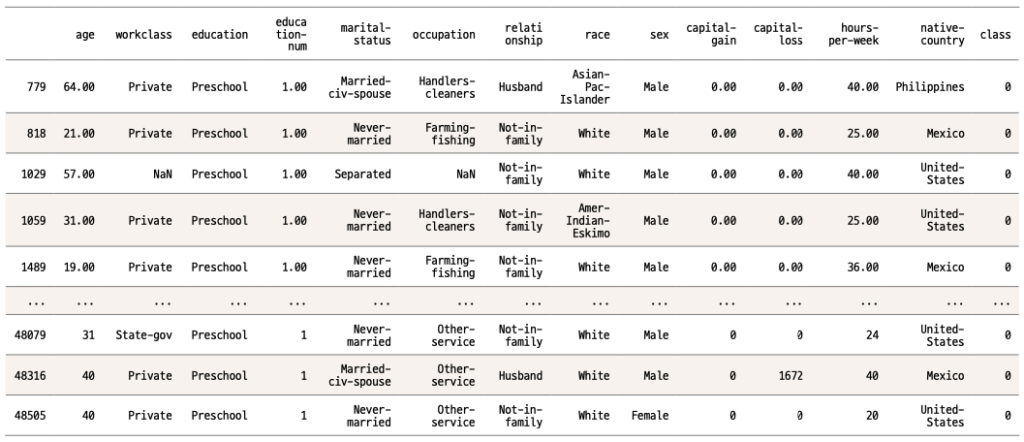
data[‘education-num’] == 1의 결과는 True 아니면 False입니다. 이 결과를 인덱스에 다시 넣음으로써 education-num이 1인 경우만 불러왔습니다. 이게 판다스에서 가장 기본적으로 필터링하는 방법이오니 잘 알아둡시다.
다음은 이 안에서 education이 어떤 종류가 있는지를 확인하기 위하여 해당 변수를 인덱싱하고 unique( ) 함수를 쓰겠습니다.
data[data['education-num'] == 1]['education'].unique()
# education-num이 1인 데이터들의 education 고윳값 확인
array(['Preschool'], dtype=object)

이번에는 모든 숫자에 대해 확인하겠습니다.
for i in np.sort(data['education-num'].unique()):
print(i, data[data['education-num'] == i]['education'].unique())
# education-num의 고윳값별 education의 고윳값 확인
1 ['Preschool'] 2 ['1st-4th'] 3 ['5th-6th'] 4 ['7th-8th'] 5 ['9th'] 6 ['10th'] 7 ['11th'] 8 ['12th'] 9 ['HS-grad'] 10 ['Some-college'] 11 ['Assoc-voc'] 12 ['Assoc-acdm'] 13 ['Bachelors'] 14 ['Masters'] 15 ['Prof-school'] 16 ['Doctorate']
그리고 print 부분에는 해당 education-num의 숫자와, 그에 응하는 education 고윳값들을 동시에 보여주기 위해서 이 둘을 같이 넣어줍니다.
완전히 우리가 기대했던 형태의 결과입니다. 낮은 숫자부터 높은 숫자까지, 점점 고학력순으로 나열되어 있습니다. 우리가 하려던 작업이 이미 별도의 변수로 마련이 되어 있습니다. (중복 정보이므로) 별도의 작업 없이 기존 변수를 drop( ) 함수로 제거시킵니다.
data.drop('education', axis=1, inplace= True)
1.4 occupation 변수 처리
다음은 occupation 변수를 살펴보겠습니다.
data['occupation'].value_counts()
Prof-specialty 6172 Craft-repair 6112 Exec-managerial 6086 Adm-clerical 5611 Sales 5504 Other-service 4923 Machine-op-inspct 3022 Transport-moving 2355 Handlers-cleaners 2072 Farming-fishing 1490 Tech-support 1446 Protective-serv 983 Priv-house-serv 242 Armed-Forces 15 Name: occupation, dtype: int64
다양한 직업군이 표기되는데, 이미 비슷한 직업군끼리는 묶인 상태로 정리된 데이터로 보입니다. 예를 들어 Farming과 fishing이 하나의 이름으로 묶여 있습니다. 유사한 직업군끼리 묶여 있지 않았다면 이를 묶는 작업을 하려했으나 이미 정리가 되어 있고, 각 직업 간의 서열이라고 할 만한 않았다면 이를 묶는 작업을 하려했으나 이미 정리가 되어 있고, 각 직업 간의 서열이라고 할 만한부분도 딱히 정의할 수가 없습니다. 더미 변수로 변환을 하면 변수 14개가 생기겠군요. 그 정도면 감당할 수 있는 수준이니 별도의 작업을 하지 않고 나중에 더미 변수로 처리하겠습니다.
1.5 native-country 변수 처리
마지막으로 native-country 변수를 살펴보겠습니다.
data['native-country'].value_counts()
United-States 43832 Mexico 951 Philippines 295 Germany 206 Puerto-Rico 184 Canada 182 El-Salvador 155 India 151 Cuba 138 England 127 China 122 South 115 Jamaica 106 Italy 105 Dominican-Republic 103 Japan 92 Guatemala 88 Poland 87 Vietnam 86 Columbia 85 Haiti 75 Portugal 67 Taiwan 65 Iran 59 Greece 49 Nicaragua 49 Peru 46 Ecuador 45 France 38 Ireland 37 Hong 30 Thailand 30 Cambodia 28 Trinadad&Tobago 27 Yugoslavia 23 Outlying-US(Guam-USVI-etc) 23 Laos 23 Scotland 21 Honduras 20 Hungary 19 Holand-Netherlands 1 Name: native-country, dtype: int64
수많은 값이 있습니다. 그리고 특이사항으로 United-States가 압도적으로 큰 비중을 차지합니다. 그럼 해당 변수를 처리하는 여러 방법을 살펴봅시다. 우선 이 경우는 United-States가 약 90%를 차지하고 있기 때문에, 아주 단순하게는 United-States 이외의 국가들을 하나로 묶어 Others 같은 이름으로 변경하는 방식도 가능합니다. 데이터가 간소화되는 장점이 있으나, 그만큼 정보가 줄어드는 단점이 있습니다. 만약 해당 예측 모델에서 United-States가 아닌 국가 사이에 큰 차이가 없다면 이 방법을 써도 무방합니다. 또 다른 방법으로는 비슷한 값들끼리 묶는 겁니다. 예를 들어 지역별로 묶는 거죠. 즉, North America, South America, Asia 등과 같이 구분할 수 있습니다. 이 방법 또한 해당 지역에 속한 국가끼리 어느 정도 유사성을 보여야 무리가 없습니다. 여기서 말하는 유사성은, 종속변수의 값에 대한 유사성을 의미합니다. 즉 국가별로 class에 대한 평균값을 내었을 때, 만약 Asia 국가들이 다소 비슷한 수치를 보여준다면 이렇게 묶는 데에 큰 무리가 없을 겁니다. 유사성은 처음에 말한 United-States 이외의 국가들끼리 묶는 때도 필요하니 국가별로 class값의 평균을 확인해봅시다.
국가별 평균을 확인해야 하기 때문에 groupby( ) 함수를 사용하여 국가별로 묶어주겠습니다.

우리는 국가별로 class의 평균값을 볼 것이기 때문에 mean( ) 함수를 사용하겠습니다.
# 아래 코드는 참고용이므로, 실행할 필요가 없습니다.
data.groupby('native-country').mean() # 그룹별 평균 계산
여기까지만 코드를 작성해도 원하는 아웃풋을 볼 수 있으나, 국가가 너무 많아서 쉽게 눈에 들어오는 상황은 아닙니다. 같은 지역에 있는 국가들끼리 비슷한 수준의 class 평균값을 가지는지를 확인하는 것이 목적이므로 지역 혹은 class 기준으로 정렬시키겠습니다. 이 데이터에는 지역에 대한 변수가 없어, class 기준으로 정렬시키겠습니다.
data.groupby('native-country').mean().sort_values('class')
# 그룹별 평균 계산 후 class 기준으로 오름차순 정렬
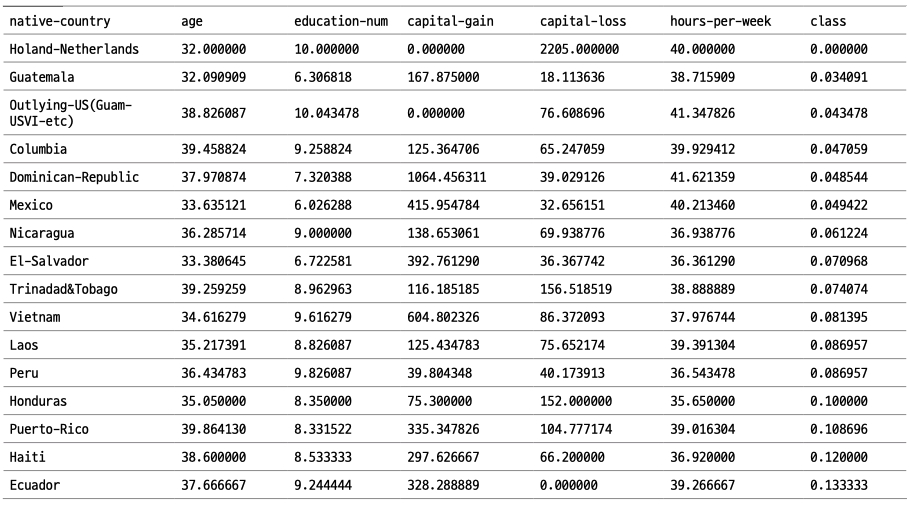
우선 다른 국가들을 Others로 묶어줄 수 있는지 ❶ ****United-States를 먼저 찾아보겠습니다. class 평균값은 약 0.24입니다. 그리고 다른 국가들은 United-States의 평균값보다 크거나 작아서 전혀 비슷하지 않은 양상입니다. Others로 묶는 방법은 좋지 않아 보입니다. 그럼 지역별로 묶어줄 수 있는지 보겠습니다. class 평균이 가장 높은 ❷ ****France 중심으로 유럽 국가를 찾아보겠습니다. 극단적으로 다른 경우만 몇 개 발견하면 해당 방법이 좋지 않음이 증명되기 때문에, 수치가 낮은 쪽에 유럽 국가가 있는지를 보는 게 빠릅니다. 가장 낮게는 Holand가 있지만 관측치가 1개밖에 안 되므로 고려하지 않아도 될 것 같고, 그다음으로는 Portual이 0.18 정도로 France와 상당한 차이를 보입니다. 다른 지역의 예로 Cuba와 Dominican Republic도 각각 0.25와 0.05로 큰 차이를 보입니다. 물론 다른 많은 나라는 지역별로 비슷한 양상을 보이기도 하지만 큰 차이를 보는 경우가 많으므로 지역별로 묶는 방법은 적합하지 않습니다.
그럼 더미 변수를 사용하지 않고 각 국가명을 숫자로 변환하여 하나의 변수를 그대로 유지하는 건 어떨까요? 제가 처음 더미 변수를 설명할 때, 범주형 데이터를 무작정 숫자로 치환하여 모델링하는 방법은 결코 좋지 않다고 설명드렸습니다. 그러나 이러한 방법이 허용되는 경우가 있는데, 바로 트리 기반의 모델을 사용할 때입니다. 트리 기반의 모델은 연속된 숫자들도 연속적으로 받아들이기보다 일정 구간을 나누어 받아들이기 때문에, 트리가 충분히 깊어지면 범주형 변수를 숫자로 바꾼다고 해도 큰 문제가 없습니다.
범주형 데이터를 숫자로 치환하는 여러 방법이 있습니다. 기본적으로는 랜덤하게 번호를 부여하는 겁니다. 예를 들어 United-States는 1, Peru는 2, Guatemala는 3 등 임의의 번호를 붙여주는 거죠. 단순한 라벨링으로 생각하면 됩니다. 또 다른 방법은 우리가 value_counts( ) 함수로 확인한 숫자들을 부여하는 방법입니다. 이 방법은 종속변수인 class가 이민자 수가 많은 국가인지 적은 국가인지에 따라 유의미한 차이를 보인다면 더 유용한 변수로 활용이 될 것이고, 그렇지 못하더라도 최소한 라벨링 효과는 가지고 가게 됩니다. 단, 라벨링의 목적만으로 이 방법을 사용할 때에는 같은 값을 가지는 국가가 없는지 확인해야 하며, 이 데이터의 경우는 동수인 국가들이 있어서 적합하지 않습니다.
마지막은 우리가 groupby( ) 로 확인했던 class의 평균값을 넣어주는 방법입니다. 이는 조금 극단적인 방법인데, 예상하려는 목푯값을 독립변수의 일환으로 반영하기 때문입니다. 즉, 답을 거의 밀어넣다 시피해서 모델링하는지라 오버피팅 문제가 발생할 수 있습니다. 오버피팅 문제는 잠시 후 매개변수 튜닝에서 더 구체적으로 다루겠습니다.
‘native-counry’별로 class의 평균값을 구하는 코드를 작성하겠습니다.
country_group = data.groupby('native-country').mean()['class']
# 그룹별 class의 평균값을 계산하여 저장
앞서 작성한 코드에서 정렬에 사용한 sort_values( ) 함수를 빼고, 인덱싱을 추가해 class값만 취했습니다. 그리고 아웃풋을 country_group이라는 이름으로 저장했습니다.
이렇게 평균값을 구해놓은 판다스 시리즈를 기존 데이터에 새로운 변수로 붙여넣어야 합니다. join( ) 이나 merge( ) 를 사용할 수 있는데 이번에는 merge( ) 를 사용해서 데이터를 합치겠습니다.

국가 이름이 키값이 되어야 하는데 현재 country_group에서 국가 이름은 변수가 아닌 인덱스에 자리하고 있습니다. reset_index( ) 를 써서 변수로 뺄 수 있습니다.
reset_index( )를 써서 인덱스를 변수로 빼주겠습니다.
country_group = country_group.reset_index() # 인덱스를 변수로 불러냄
이제 country_group( ) 을 확인하면 다음과 같은 데이터프레임을 확인할 수 있습니다.
country_group # 데이터 확인

이제 merge( ) 를 사용하여 두 데이터를 합치겠습니다.
data = data.merge(country_group, on = 'native-country', how='left')
# data와 country_group을 native_country 기준으로 결합 (left join)
data 국가 이름은 기준으로 하여 country_group을 붙이는 형태이기 때문에 data를 메인으로 삼아 merge( )를 실행했습니다. 키값은 native-country, 결합 형태는 왼쪽 조인(3.1.8절 ‘데이터프레임 합치기’)으로 처리해줍니다.
그럼 데이터가 잘 합쳐졌는지 data를 불러서 확인해봅시다.
data # 데이터 확인
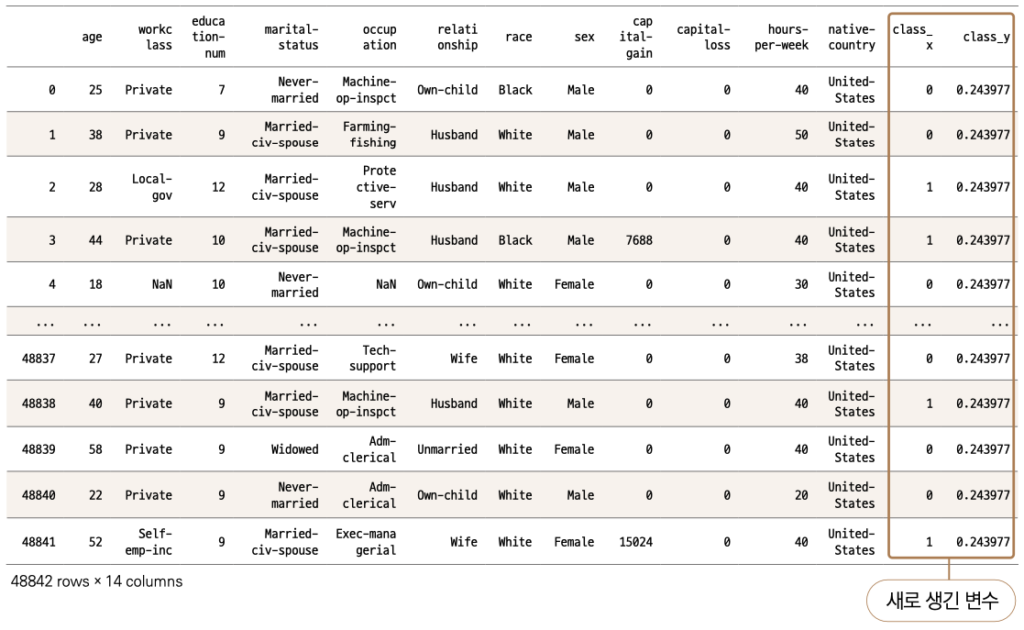
합쳐지기는 했는데 문제가 하나 발생했군요, class_x와 class_y라는 변수가 생겼습니다. 기존의 data에 class 변수가 있고, country_group에도 class 변수가 있다 보니, 컬럼 이름이 겹치는 바람에 판다스에서 자동적으로 변경시켜버렸습니다. 우리는 class_y를 국가명 대신 사용해줄 것이기 때문에 기존 native-country를 삭제하고 → class_y를 해당 이름(native-country)으로 바꾸고 → class_x를 class로 다시 변경해주겠습니다.
data.drop('native-country', axis=1, inplace=True) # 변수 제거
data = data.rename(columns= {'class_x': 'class', 'class_y': 'native-country'}) # 변수 이름 변환
여기서 컬럼 이름을 바꾸는데 rename( ) 함수를 사용했습니다. rename( ) 함수는 위에서 보시는 것처럼 변경할 대상(columns 혹은 index)을 지정해주시고 구체적인 변경 사항은 딕셔너리 형태로 매핑해주면 됩니다.

2. 전처리 : 결측치 처리 및 더미 변수 변환
결측치를 처리합시다. 먼저 결측치가 있는 변수들과 그 비율을 확인하겠습니다.
data.isna().mean() # 결측치 비율 확인
age 0.000000 workclass 0.057307 education-num 0.000000 marital-status 0.000000 occupation 0.057512 relationship 0.000000 race 0.000000 sex 0.000000 capital-gain 0.000000 capital-loss 0.000000 hours-per-week 0.000000 class 0.000000 native-country 0.017546 dtype: float64
총 3개의 변수에서 결측치가 보입니다. workclass와 occupation은 약 5%, native-country는 1.7% 정도입니다. 우선 native-country는 각 국가별 class의 평균값으로 대체한 상태입니다. 원래는 범주형 변수이기 때문에 평균치로 채우는 것이 불가능하지만 지금은 숫자로 바뀌었고 그 숫자가 마침 class의 평균값이기 때문에, mean( ) 이나 median( ) 으로 결측치를 채우는 것도 가능합니다. 또는 완전 별개의 숫자를 지정하여 채워주는 방법도 가능합니다. 보통 결측치를 숫자로 채워줄 때 -9나 -99와 같은 임의의 숫자를 사용합니다. 이렇게 임의의 숫자를 채워주는 것은 트리 기반 모델에서는 큰 문제가 없으나 선형 모델에서는 데이터의 왜곡을 불러오니 주의해야 합니다. 지금은 두 가지 방법 모두 가능한데, 여기에서는 -99를 채우겠습니다.
data['native-country'] = data['native-country'].fillna(-99) # 결측치를 -99로 대체
workclass와 occupation 변수는 모두 범주형 변수이기 때문에 평균치로 해결할 수가 없습니다. 이 경우는 특정 텍스트를 채워주거나, dropna( )로 해당 라인을 제거해야 하는데, 우선 각 컬럼의 value_counts( ) 출력물을 보고 판단하겠습니다.
data['workclass'].value_counts() # 고윳값별 출현 빈도 확인
Private 33906 Self-emp-not-inc 3862 Local-gov 3136 State-gov 1981 Self-emp-inc 1695 Federal-gov 1432 Without-pay 21 Never-worked 10 Name: workclass, dtype: int64
workclass에서는 ❶ Private 비율이 압도적입니다. 특정 값이 대부분을 차지하는 경우라면 해당 값으로 결측치를 채워주는 방법도 무난합니다. Private이 70% 정도라서 조금 아쉬운 부분은 있지만, 연습 차원에서 이 값으로 결측치를 채워넣겠습니다.
data['workclass'] = data['workclass'].fillna('Private')
# 결측치를 Private으로 대체
다음으로 occupation 컬럼을 확인하겠습니다.
data['occupation'].value_counts()
Prof-specialty 6172 Craft-repair 6112 Exec-managerial 6086 Adm-clerical 5611 Sales 5504 Other-service 4923 Machine-op-inspct 3022 Transport-moving 2355 Handlers-cleaners 2072 Farming-fishing 1490 Tech-support 1446 Protective-serv 983 Priv-house-serv 242 Armed-Forces 15 Name: occupation, dtype: int64
이번에는 어떤 특정값이 압도적으로 많다고 하기가 어렵습니다. 이런 경우에는 알맞지 않습니다. 별도의 텍스트 ‘Unknown’으로 채워보겠습니다.
data['occupation'] = data['occupation'].fillna('Unknown')
# 결측치를 Unknown으로 대체
이제 모든 결측치를 해결했으니, 범주형 데이터를 더미 변수로 변환하겠습니다.
data = pd.get_dummies(data, drop_first=True) # 더미 변수로 변환
3편은 모델링 및 평가, 그리고 결정 트리가 어떤 원리로 작동되는지 살펴봅시다.

삼성전자에 마케팅 직군으로 입사하여 앱스토어 결제 데이터를 운영 및 관리했습니다. 데이터에 관심이 생겨 미국으로 유학을 떠나 지금은 모바일 서비스 업체 IDT에서 데이터 사이언티스트로 일합니다. 문과 출신이 미국 현지 데이터 사이언티스트가 되기까지 파이썬과 머신러닝을 배우며 많은 시행착오를 겪었습니다. 제가 겪었던 시행착오를 덜어드리고, 머신러닝에 대한 재미를 전달하고자 유튜버로 활동하고 책을 집필합니다.
현) IDT Corporation (미국 모바일 서비스 업체) 데이터 사이언티스트
전) 콜롬비아 대학교, Machine Learning Tutor, 대학원생 대상
전) 콜롬비아 대학교, Big Data Immersion Program Teaching Assistant
전) 콜롬비아 대학교, M.S. in Applied Analytics
전) 삼성전자 무선사업부, 스마트폰 데이터 분석가
전) 삼성전자 무선사업부, 모바일앱 스토어 데이터 관리 및 운영
강의 : 패스트캠퍼스 〈파이썬을 활용한 이커머스 데이터 분석 입문〉
SNS : www.youtube.com/c/데싸노트

